Optimising a slow stored procedure

In this blog post, I describe optimising a slow stored procedure. It’s part of a series of posts by members of the SQL Server community in relation to T-SQL Tuesday. For this month’s T-SQL Tuesday, Kerry Tyler asks:
Tell me (us all, obviously) about something recently that broke or went wrong, and what it took to fix it. Of course, the intent here would be for this to be SQL Server-related, but it doesn’t have to be. We can all learn from something going wrong in infrastructure-land, or how there was a loophole in some business process that turned around and bit somebody’s arm. It doesn’t even have to be all that recent–maybe you’ve got a really good story about modem banks catching on fire and that’s how you found out the fire suppression system hadn’t been inspected in years. Just spitballin’ here. If you’ve got an incident whose resolution can help someone else avoid the same problem in the future or improve a policy as a preventative measure, let us hear about it.
The situation
I received a call out of hours that a key web page in the application was suffering from timeouts. It was a page for managing important finance data and our team in the US were unable to work. I needed to work out what had changed and how to fix it?
Identifying the problem
All http requests are logged so I could took a quick look at the logs to see if there were any problems. It stood out that one stored procedure in particular was timing out. I quickly ran a trace (sorry xe fans) and found that one particular proc was running for 30 seconds every time. (This is the application timeout value). I took the proc name and parameters and ran from SSMS and found that the procedure took 4 minutes to complete.
How to fix
So why had this procedure suddenly gone bad? Well the fact is it was poorly performing anyway and finance users were frustrated on the whole. My first thought was recompile it quickly and see what happens. Like flicking a switch, it was back to around 20 seconds and the finance page would load again, albeit slowly. So, the issue here was that a bad execution plan had been cached and was being used for each subsequent execution.
This is however a very unsatisfactory fix. First of all, you are not stopping the problem from reoccurring. Secondly, you are only improving the situation from broken to slow. Hardly something for the CV.
The next morning, I took a look at the stored procedure code and could see it needed to be optimised. I ran the proc on a test system, and collected the key metrics such as logical reads and cpu duration by running [SQL]SET STATISTICS TIME,IO ON[/SQL]. To simplify the output, I always copy this into Richie Rump’s Statistics Parser.
This output showed me logical reads into the millions for multiple tables. Starting from the tables with the highest reads, I worked through all of the high ones, looking at which columns were being queried and which predicates were being used. I used this information to design and test alternative indexes, each time remeasuring the output from SET STATISTICS TIME,IO ON. Once I had the correct indexes in place, I was able to submit a PR with the changes. Once it went to production, it resulted in sub second page loads which made the finance team a lot happier.
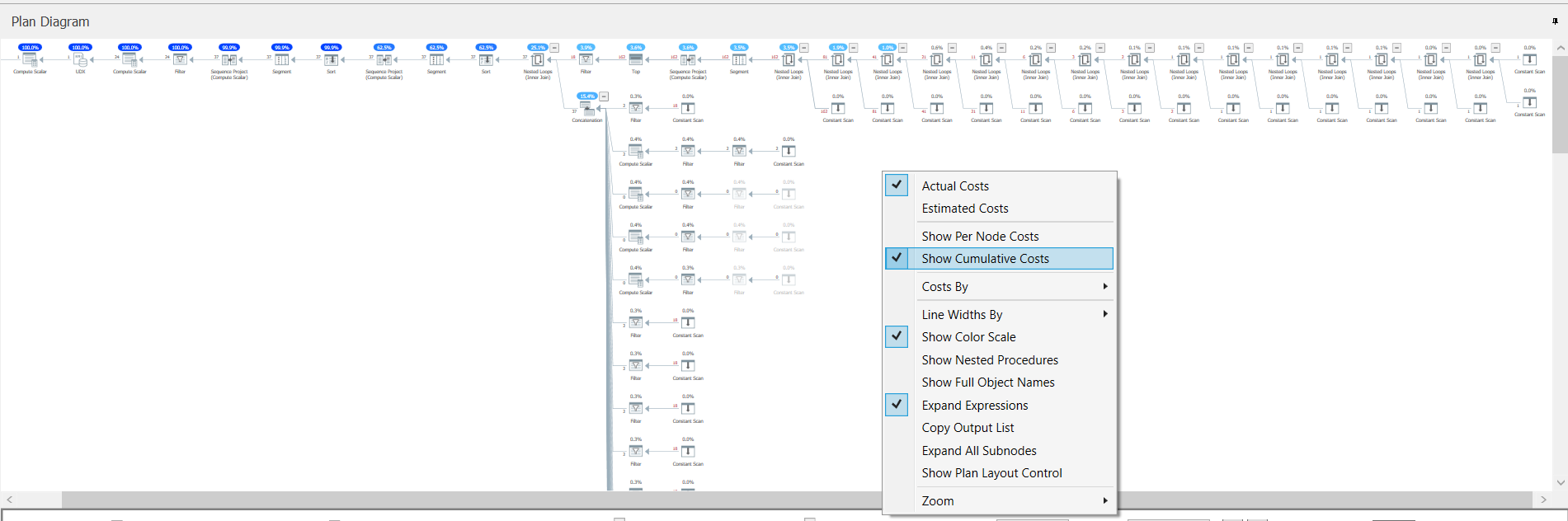
One other thing that I did that is worth mentioning is I used Sentry One Plan Explorer (It’s free). The query plan was one of those intimidating ones, with hundreds of nodes. When I look at these in SSMS, it’s sometime difficult to know where to start. However in Plan Explorer, there is an option to ‘Show Cumulative Costs’ which helps you can see which branches of the plan can be minimised as the have little cumulative impact, rather than the impact of each node within the plan. This makes reading the rest of the plan much easier because it gets a lot smaller.
[…] McCormack has “Optimising a slow stored procedure” next. John walks through his process of tuning up a stored procedure he had gotten an […]