This post is part of a planned series on 7 ways for data professionals to save money in Azure. It’s so easy for costs to escalate in the cloud, and being proactive is the best way to optimise your costs, and make sure you aren’t spending more than you need to. In this post, I look at how to cut costs by implementing an Azure IaaS SQL Backups retention policy and ensuring you are not paying for more than you need.
Azure IaaS SQL Backups
This advice is to specific on-premises or IaaS backups which are going directly into an Azure blob storage account. Whilst blob storage can be reasonably cheap, if you keep every backup with no retention policy, the costs will soon escalate.
Scenario
You have 5 databases on a SQL Server Instance. You take daily full backups of each database on your instance. You also take log backups every 15 minutes as each database is in full recovery mode. This means in 1 week, you will have 35 full backups and 3,360 transaction log backups. This multiplies to 1,820 full and 174,720 t-log backups over 52 weeks. Multiply this for 7 years or more and the costs can get very expensive.
Your company policy only requires point in time restore functionality for 2 weeks of data. On top of that, daily full backups for the previous 3 months and a weekly full backup for between 3 months and 7 years must be kept.
For simplicity, lets assume an average full backup size of 25GB and a log backup size of 100MB.
Costs with no planned retention policy
| Timescale | Full backups | Log backups | Blob storage tier (East US – GPV2 – LRS – Standard) | Monthly Cost |
| Previous 7 years (5 DBs) | 12,775 | 1,226,400 | Hot | £4,784.79 + £1856.92 £6,641.71 |
Costs with a planned retention policy
| Timescale | Full backups | Log backups | Blob Storage tier (East US – GPV2 – LRS – Standard) | Monthly Cost |
| Previous 14 days | 70 | 6,720 | Hot | £27.13 £10.42 £38.55 |
| 15 days to 93 days | 390 | 0 | Cool | £110.45 |
| 94 days to 2,555 days | 1758 | 0 | Archive | £45.40 |
| TOTAL | 2,218 | 6,720 | Mixed | £194.40 |
So if we optimise the storage to only keep the full and t-log backups that we need, and we use cool and archive storage correctly, we can save over £6,000 per month. There are four main ways to actively manage data retention in order that you optimise your cloud costs, without breaching your data retention policy.
1. Azure Blob Storage lifecycle management
Lifecycle management rules are a simple way to manage files within blob storage. You can either delete files or move them to a cheaper storage class. The rules are fairly customisable so this a basic option which works well without too much configuration.
There are huge savings to be made by moving storage to the archive tier. If you’re holding on to backups for regulatory purposes or to adhere to company policies but won’t be using them regularly, the archive tier provides great value for money. Your data may take several hours to be available when you make a request so it’s not suitable for any disaster recovery scenario but providing you don’t mind waiting, you will cut your Azure bill substantially.
2. SQL Server IaaS Agent extension
If you have SQL Server running in Azure VMs, you can opt to have them automatically backed up by the SQL Server IaaS Agent Extension. Whilst there is some customisation available, you can’t retain your backups beyond 30 days. This makes it unsuitable for our scenario here but if all you need is 30 days or fewer, then this is a great option. Having Azure automatically handle the backups, gets you one step closer to Platform as a Service whilst still retaining the flexibility or running a full SQL Server instance.
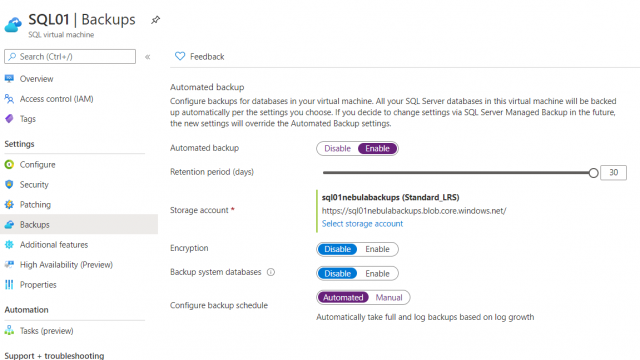
Automated backups for SQL Server 2014
Automated backups for SQL Server 2016+
3. Azure Backup (SQL Server VMs)
You can use Azure backup, via recovery services vault to configure backups on multiple servers. You can choose to back up specific databases or all, including any new ones added after configuration by selecting AUTOPROTECT. There are very detailed retention options which allow you to set a very fine grained retention policy.
4. Roll your own solution
This isn’t needed as much as it used to be. It used to be the case that the lifecycle rules were very inflexible and to keep certain backups, and change storage options, you needed to use your own script. My preferred choice was using PowerShell and Azure Automation Runbooks. With one client, this solution saved hundreds of thousands of pound per year.
* I would only recommend this if the two options above don’t provide you with the flexibility you need to manage your storage retention, according to your own complex requirements.
P.S Don’t forget backup compression
With all of these solutions, don’t forget to enable compression on your backups. This will help you save even more money in addition to the retention policy you have just put in place.