In this post, I discuss 3 methods (of varying complexity) to carry out some disk space monitoring with SQL server. This can be ad-hoc or you can build it into SQL agent jobs to run on a schedule. Now the first thing I’d like to say is this isn’t a replacement for good monitoring software, it’s more of a compliment to monitoring software. It’s a double check in case something goes wrong with your monitoring. Having some handy scripts is useful as well, because it lets you find out info on an ad-hoc basis, rather than relying on alerts or checking manually. [Read more…]
Compressing backups with Litespeed for SQL Server
I recently looked at an issue where free space on a backup drive was running low. One option was to increase the storage. Another was to look at the composition of the backups and see if I could try compressing backups with Litespeed for SQL Server.
2 particular backups stood out. Database1 was 93GB and Database2 was 297GB. Incidently, this was only half of the total size as we stripe across 2 drives so the total size was 186GB and 594GB.
Example backup script for Litespeed.
[sql]
exec master.dbo.xp_backup_database
@database = ‘Database1’,
@filename = ‘D:\Backup\Database1\Database1_1.BKP’,
@filename = ‘G:\Backup\Database1\Database1_2.BKP’,
@backupname = Database1 backup’,
@desc = ‘Backup of Database1’,
@encryptionkey = ‘LiteSp1234567’,
@cryptlevel = 8,
@init = 1,
@logging = 0,
@throttle = 99,
@comment = ”,
@with = ‘SKIP’,
@with = ‘STATS = 5’,
@compressionlevel = 1
[/sql]
For the purposes of this post, the line we are most interested in is @compressionlevel = 1. By increasing @compressionlevel on a scale from one to eight, we can reduce the size of our backups. One thing to note is that the higher the level of compression, the higher the CPU utilisation will be. More highly compressed backups will usually take more time. It is worth testing the backups using incremental increases in @compressionlevel to find the one that best suits your server.
LiteSpeed for SQL Server 7.5 allows a compression level of 1 – 8.
1 = Medium Compression
2 = Medium High Compression
3-6 = High Compression
7-8 = Extreme Compression.
(Previous versions allowed 9-11 but these are now classed as Level 8)
It is worth testing the backups using incremental increase in @compressionlevel to find the one that best suits your server.
My results:

In the end, I opted for @compressionLevel = 5 for Database1 and @CompressionLevel = 3 for Database2. The increased backup time to use @compressionlevel=5 for Database1 is justifed, given the 64GB reduction in backup size. For Database 2 backup, there was too large a jump in processing time between levels 3 and 5. If we had no option, we could live with it but the original reduction in size by using @CompressionLevel = 3 was sufficient.
Side note: As a side benefit I wasn’t considering, our backup team advised the tape backup duration reduced by 1.5 hours so there was a positive knock on effect for another team too.
Troubleshooting Transactional Replication in SQL Server
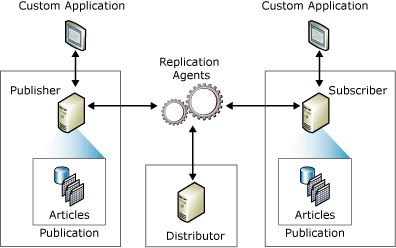 This might make me the odd one out but I actually really like replication. It took me a while to get comfortable with it but when I did and when I learned how to troubleshoot transactional replication confidently, I became a fan. Since I exclusively use transactional replication and not snapshot replication or merge replication, this post is only about transactional replication and in particular, how to troubleshoot transactional replication errors.
This might make me the odd one out but I actually really like replication. It took me a while to get comfortable with it but when I did and when I learned how to troubleshoot transactional replication confidently, I became a fan. Since I exclusively use transactional replication and not snapshot replication or merge replication, this post is only about transactional replication and in particular, how to troubleshoot transactional replication errors.
In the production system I work on, replication is highly reliable and rarely if ever causes the DBA’s headaches. It can be less so in our plethora of dev and qa boxes, probably down to rate of change in these environments with regular refreshes. Due to this, I’ve had to fix it many times. As I explain how I troubleshoot replication errors, I assume you know the basics of how replication works. If you don’t, a really good place to start is books online. It describes how replication uses a publishing metaphor and describes all the component parts in detail.
Style over substance
When it comes to managing emails, I can easily receive about 600 a day. This is probably far too many (although that’s a subject for another day). The challenge with receiving so many emails, especially so many system generated errors and warnings is that they can fail to stand out. Important information can be missed. A lack of formatting can also make it difficult to understand what the problem is, if any.
Here is an example of a boring system generated message.
 To get around this, I always try to use some pretty HTML in my output just to help with the appearance and to make the message easier to read. I don’t go overboard, just a header tag, something like <h4> is usually enough (unless you want it really big) and of course I like to include my output in a table, usually with a splash of colour in the table header.
To get around this, I always try to use some pretty HTML in my output just to help with the appearance and to make the message easier to read. I don’t go overboard, just a header tag, something like <h4> is usually enough (unless you want it really big) and of course I like to include my output in a table, usually with a splash of colour in the table header.
Index maintenance using Ola Hallengren’s scripts
Having recently set up Index maintenance using Ola Hallengren’s scripts on a range of my company’s production servers, I wanted to write about the steps involved including some custom steps to ensure the overall health of the SQL Server database.
The aim of this blog post is to be not too technical, I don’t cover what Ola has documented on his site however I do include scripts for my custom steps. I will only cover index maintenance, although these scripts give the options for statistics maintenance also. This is because we already had a custom solution for statistics maintenance that was working great, whereas we needed to make improvements to our index maintenance solution.
- « Previous Page
- 1
- …
- 5
- 6
- 7