Terminology matters: Locks, blocks and deadlocks
I’ve lost count of how many times people have told me there is deadlocking in the database, only to check and see no deadlocks have occurred. In this scenario, it is usually blocking they are trying to describe. As DBAs or developers, it is important to know the difference between locks, blocks and deadlocks.
Read on, or just skip to the video
What are SQL Server locks
Locks are essential for ensuring the ACID properties of a transaction. Various SELECT, DML and DDL commands generate locks on resources. e.g. In the course of updating a row within a table, a lock is taken out to ensure the same data cannot be read or modified at the same time. This ensures that only data that is committed to the database can be read or modified. A further update can take place after the initial one, but they cannot be concurrent. Each transaction must complete in full or roll back, there are no half measures.
It should be noted that isolation levels can have an impact on the behaviour of reads and writes, but this is generally how it works when the default isolation level is in use.
Lock types
I don’t want to write a full post about lock types, mainly because the ultimate guide already exists, along with a matrix showing lock compatibility across all possible lock combinations. For a simple explanation of the basics:
- If data is not being modified, concurrent users can read the same data.
- As long as the isolation level is the SQL Server default (Read Committed)
- This behaviour changes however if a higher isolation level such as serializable is being used.
- If data is being modified, the select query will have to wait on acquiring the shared lock it needs to read data.
What is blocking
Blocking is the real world impact of locks being taken on resources and other lock types being requested which are incompatible with the existing lock. You need to have locks in order to have blocking. In the scenario where a row is being updated, the lock type of IX or X means that a simultaneous read operation will be blocked until the data modification lock has been released. Similarly, data being read blocks data from being modified. Again, there are exceptions to these based on the isolation level used.
Blocking then is a perfectly natural occurrence within SQL Server. In fact, it is vital to maintain ACID transactions. On a well optimised system, it can be hard to notice and doesn’t cause problems.
Problems occur when blocking is sustained for a longer period of time, as this leads to slower transactions. A typical connection timeout from a web app is 30 seconds so anything above this leads to lots of exceptions. Even at 10 or 15 seconds, it can lead to frustrated users. Very long blocking can bring full servers to a stand still until the lead blockers have cleared.
Identifying blocking
I simply use Adam Machanic’s sp_whoisactive stored procedure. You could use sp_who2 if you absolutely can’t use 3rd party scripts, but this proc is pure t-sql so argue your case.
EXEC sp_whoisactive @find_block_leaders = 1
To kill or not to kill
Sometimes you may have no option but to kill spids in order to clear blocking but it is not desirable. I’m generally a bit happier killing a select query if it is causing blocking, because it won’t result in a DML transaction failing. It might just mean that a report or user query fails.
Multiple identical blockers
If you have multiple blockers and they are all similar or identical, it could mean that an end user is rerunning something that keeps timing out on the app layer. These app timeouts don’t correlate to SQL timeouts so it can be the case that user just keeps hitting f5, oblivious that this is making the problem worse. I’m a lot happier killing these spids, but it’s important to say to the end user where possible, so they don’t keep doing the same thing.
It could also be that a piece of code which is called regularly has regressed and no longer completes quickly. You’ll need to fix this or the blocking headache won’t go away.
What are deadlocks?
Deadlocks occurs when two or more processes are waiting on the same resource as well as waiting on the other process to finish before they can move on. With a scenario like this, something has got to give or they will be in a stand off until the end of time. They are resolved by SQL Server picking a victim, usually the least expensive transaction to roll back. This is like having one of your blocking queries automatically killed to get things moving again. It’s far from ideal, leads to exceptions and may mean that some data intended for your database never got there.
How to check for deadlocks
I like to use sp_blitzlock from Brent Ozar’s first responder kit. If I’m in firefighting mode, I’ll just check for the previous hour. You can also pick out deadlocks from the SQL Server Error Log, or you can set up extended events to capture them.
-- Deadlocks in last hour DECLARE @StartDateBlitz datetime = (SELECT DATEADD(HH,-1,GETDATE())),@EndDateBlitz DATETIME = (SELECT GETDATE()) EXEC sp_BlitzLock @EndDate = @EndDateBlitz, @StartDate = @StartDateBlitz
Simulating blocking
If you want to simulate blocking, you can try this on the the Wide World Importers database.
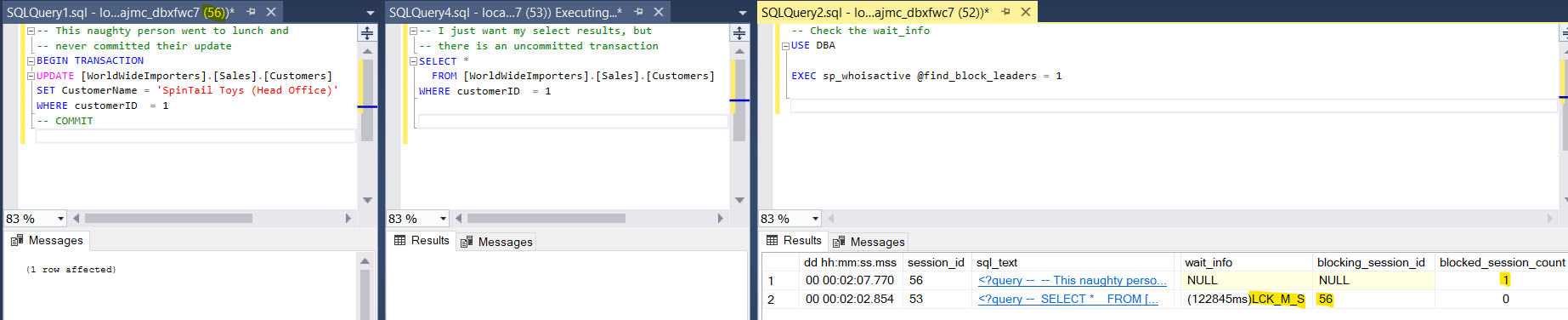
/* Run each of these, in order, in a different SSMS window. */ -- Query 1 (This naughty person went to lunch and never committed their update) BEGIN TRANSACTION UPDATE [WorldWideImporters].[Sales].[Customers] SET CustomerName = 'SpinTail Toys (Head Office)' WHERE customerID = 1 -- COMMIT -- Only run the commit above after all the queries have been run and you have observed blocking. Query 2 will finish instantly. -- Query 2 (I just want my select results, but there is an uncommitted transaction blocking me) SELECT * FROM [WorldWideImporters].[Sales].[Customers] WHERE customerID = 1 -- Query 3 (Check the wait_info) USE DBA EXEC sp_whoisactive @find_block_leaders = 1 -- You should see a wait type of LCK_M_S on your select query. This means the thread is waiting to acquire a shared lock.
The image below shows the output of the 3 queries side by side. Query 1 completes quickly, but notice it is uncommitted. Query 2 will not complete until Query 1 is committed or rolled back. Running Query 3 (sp_whoisactive) lets you know which spids are causing the blocking and which are being blocked.
I’ve tried to keep the post on locks, blocks and deadlocks about the differences. I haven’t gone too technical with isolation levels, wait types or lock compatibility. The post is aimed at newer DBAs and developers to help them grasp the technology and understand the distinct purposes of locks, blocks and deadlocks.