Performance tuning project
I’m coming to the end of what has been a successful performance tuning project for SQL Server. I wanted to share some of the things that made it a success.
Corporate buy in
The company had a goal to improve the page load times of a number of key pages within our application. This was to improve the user experience for our customers. They acknowledged that the database code, both indexes and stored procedures needed optimsation but so too did aspects of the application code. It was good to see this acknowledged as I’ve been in many situations where the database takes all the blame.
The company approved a considerable amount of resource in terms of personnel to work solely on this stability and optimisation project. It included senior developers, testers and a project manager. I was brought in to look at the database performance. Whilst some business as usual (BAU) priorities did come in from time to time, a large core of the team was protected from this and allowed to get on with the work of making the system go faster, thus improving the customer experience.
Daily standups
We held daily standups where we covered what we had done since the last meeting, what we were working on and if anything was blocking our progress. These were kept short so as to not get in the way of the development work, but allowed everyone an overview of what the other team members were working on. Often, as a result of these, side conversations spun up and team members helped out others who were looking for a bit of assistance. (Or simply to bounce ideas around)
Collaboration
The team were willing to help each other. When Pull Requests (PRs) were submitted, these were swiftly approved where there were no objections, or challenged in a positive way which helped get the best overall result. When the API calls were showing as slow, but nothing was obvious on the SQL server, heads were put together to use the tools at our disposal to get to the root cause. This often included Azure App Insights which I had not previously used, and this helped us get the end to end transaction details. We could pull out the SQL for any areas which were slow and work on making it perform better.
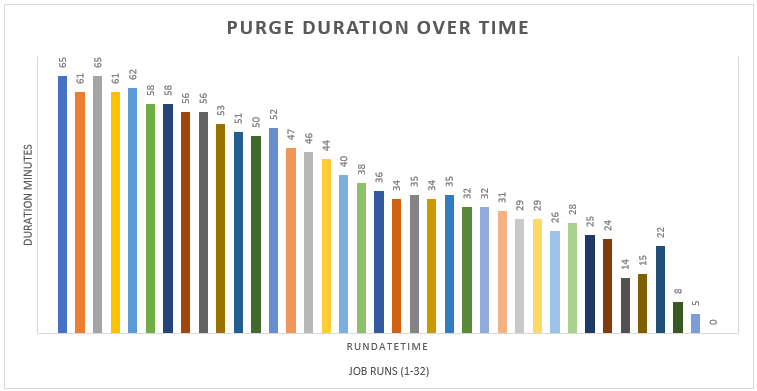
Measuring improvements
The Azure Instance class for the SQL Server had previously been doubled so there was no appetite to scale it up again. The hope was that we may eventually be able to scale back down after a period of stability.
The system previously had issues with blocking, high CPU and slow durations so I wanted to reduce page reads, CPU and duration for all of the SQL calls I was working on. I wouldn’t consider a PR if at least 2 of these metrics were not improved. My main focus was on reducing duration of calls but I didn’t want to improve one thing, and make others worse as a consequence. In my own tickets, I always made sure to document the before and after metrics from my standalone testing so as to give confidence that they would be included in upcoming releases.
We also used Apdex which is a standardised way of measuring application performance. It ranks page views on whether the user is satisfied, tolerating or frustrated. The more we move users out of the frustrated and tolerating groups, and in to satisfied, the higher the Apdex score will be. As our project moved through release cycles, we were able to see steady increases in our Apdex scores. Apdex also allowed us to identify what was hurting us most and create tickets based on this information.
Top Quality Load Test Environment
We had a top quality load test environment which used production masked backups for the databases. I set up the availability groups to match production, the servers were all sized the same as production and had the same internal settings such as tempdb size, sp_configure settings and trace flags etc. We were able to replay the same tests over and over again using Gatling, and our testers made really useful reports available to help us analyse the performance of each hotfix. If it was a proven fix, it was promoted to a release branch, if it wasn’t, it was binned.
End Game
This intensity was kept up for the almost 2 months and it was ultimately transformative for the business. Whilst there are still many further improvements that can be made, the specialised squad is being disbanded and team members are being reallocated to other squads. Performance should be a way of life now, rather than an afterthought or another performance tuning project.
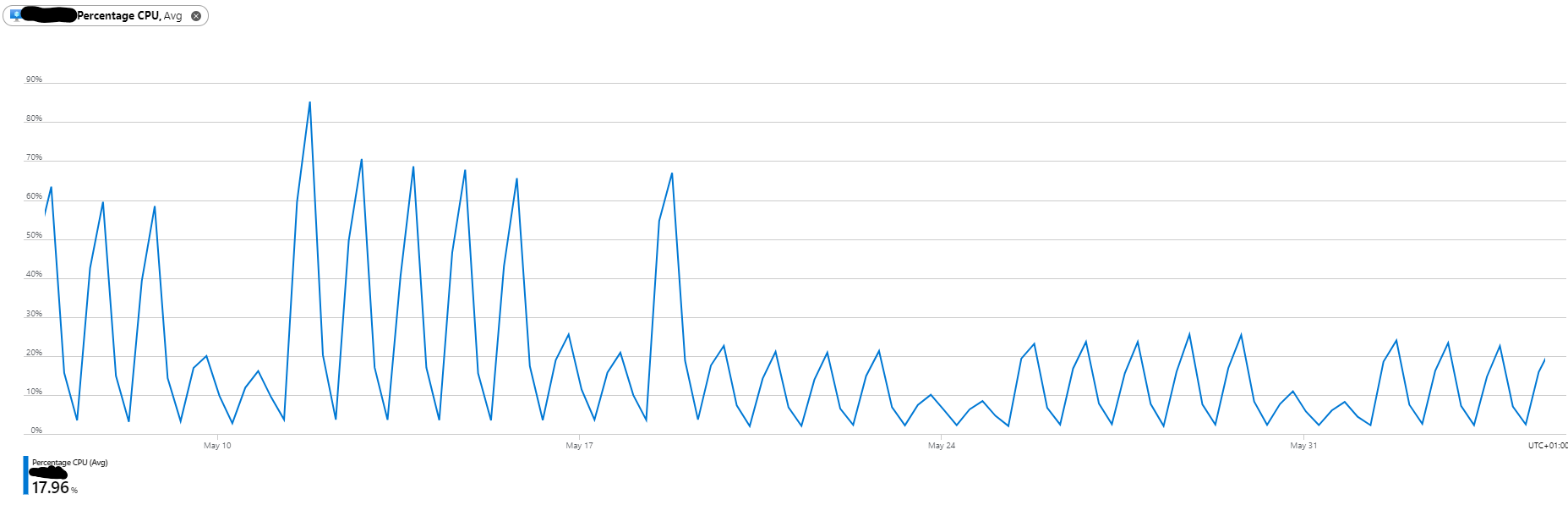
We can be happy that we improved the Apdex scores, sped up a huge number of regularly used SQL transactions, and removed the large CPU peaks that dominated our core business hours.
If you enjoyed this, you may also enjoy some of these other posts.
 Maintenance of SSISDB within SQL Server
Maintenance of SSISDB within SQL Server
 My presentation
My presentation






