AWS Athena
 This post answers “What is AWS Athena” and gives an overview of what AWS Athena is and some potential use cases. I discuss in simple terms how to optimize your AWS Athena configuration for cost effectiveness and performance efficiency, both of which are pillars of the AWS Well Architected Framework. My Slides | AWS White Paper.
This post answers “What is AWS Athena” and gives an overview of what AWS Athena is and some potential use cases. I discuss in simple terms how to optimize your AWS Athena configuration for cost effectiveness and performance efficiency, both of which are pillars of the AWS Well Architected Framework. My Slides | AWS White Paper.
This post was originally published on March 2018, and has subsequently been updated.
AWS’s own documentation is the best place for full details on the Athena offering, this post hopes to serve as further explanation and also act as an anchor to some more detailed information. As it is a managed service, Athena requires no administration, maintenance or patching. It’s not designed for regular querying of tables in a way that you would with an RDBMS. Performance is geared around querying large data sets which may include structured data or semi-structured data. There are no licensing costs like you may have with some Relational Database Management Systems (RDBMS) such as SQL Server and costs are kept low, as you only pay when you run queries in AWS Athena.
More info on AWS Athena
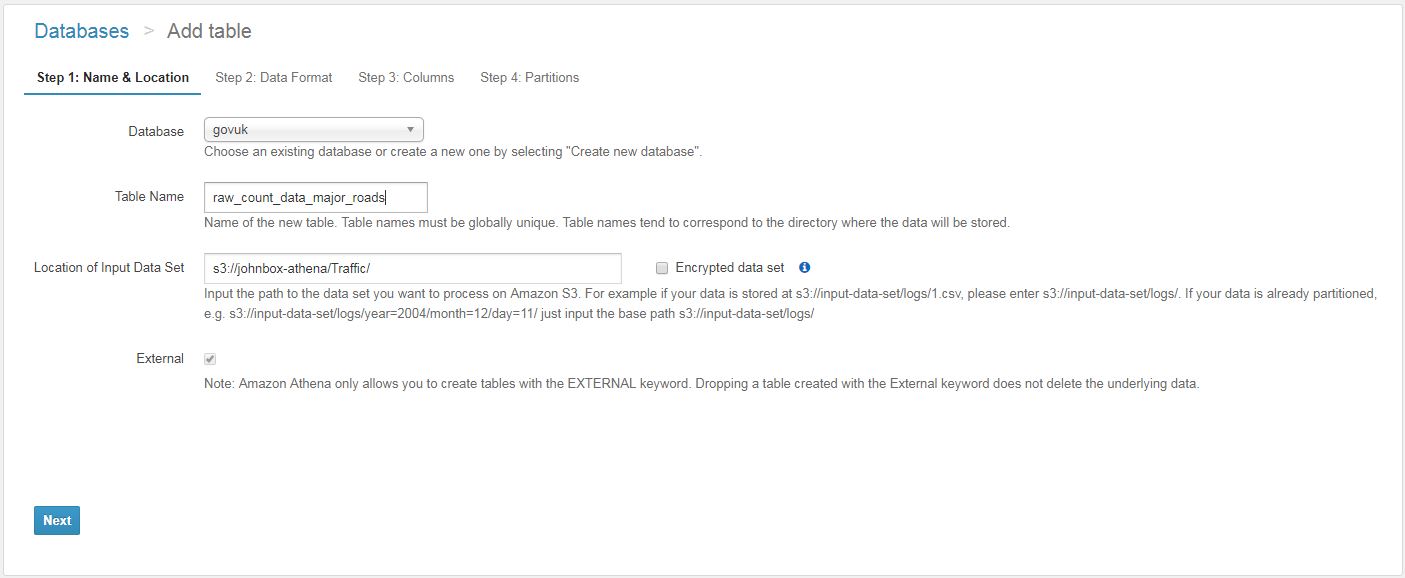
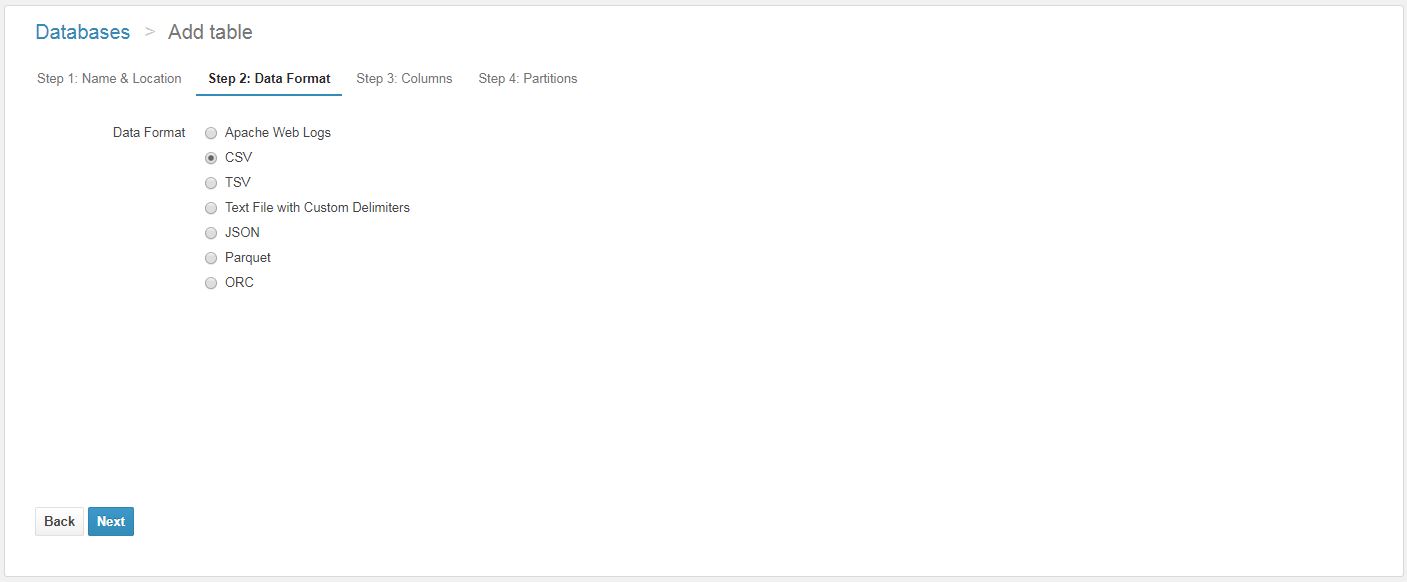
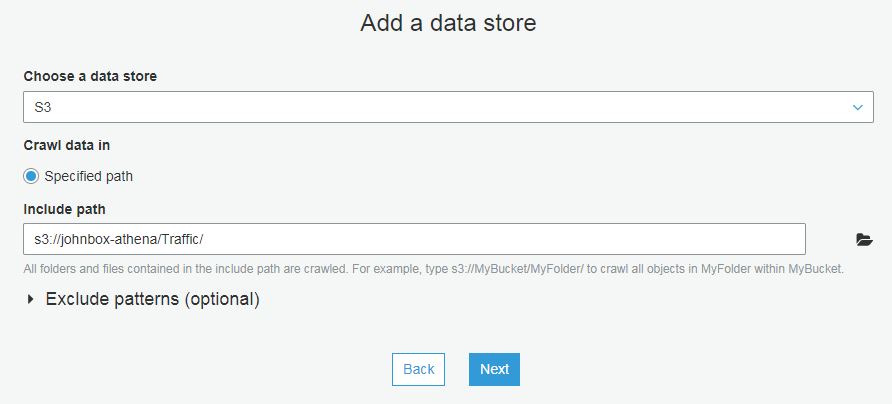
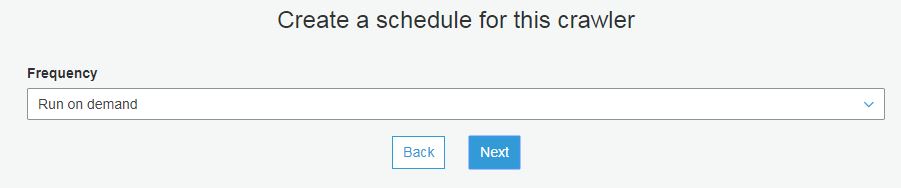
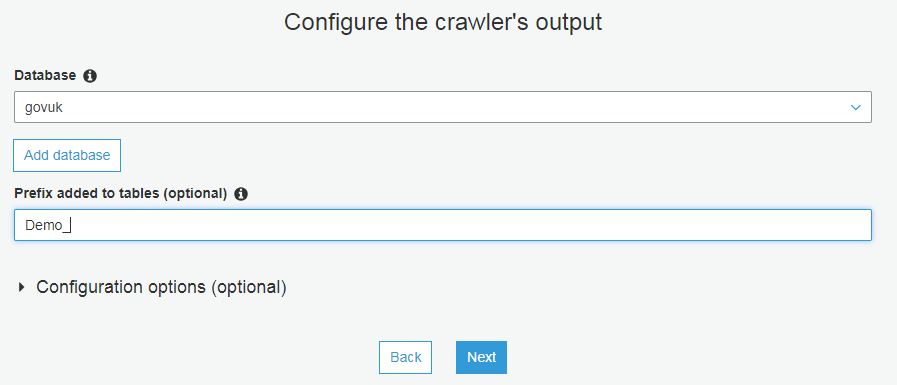
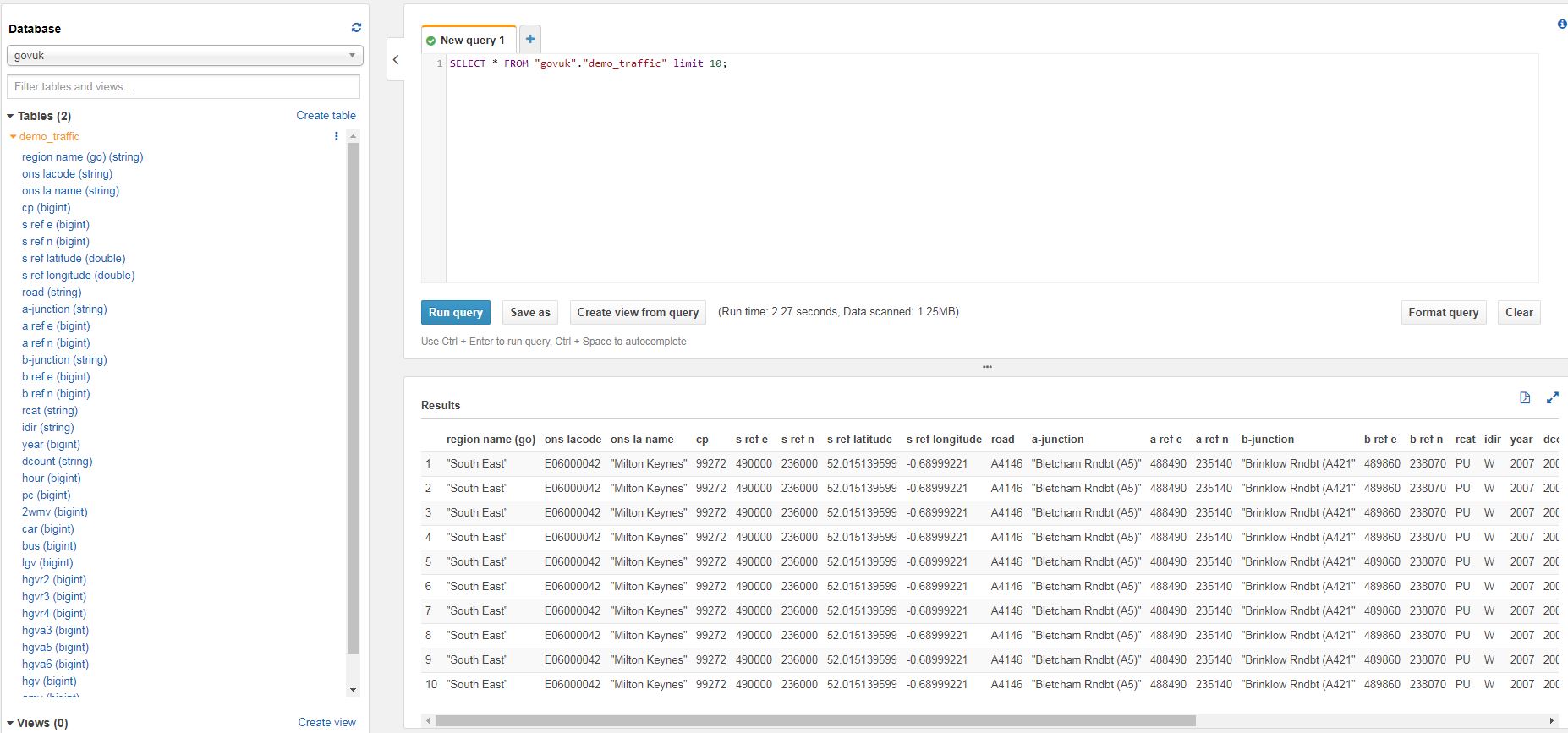
Athena is a serverless interactive query service provided by AWS to query flat files in S3. It allows users to query static files, such as CSVs (which are stored in AWS S3) using SQL Syntax. The queries are made using ANSI SQL so many existing users of database technologies such as SQL Server or MySQL can adapt quickly to using ANSI. New users can learn the commands easily.
How does it save me money?
“Object based storage” like Amazon S3 is a lot cheaper than “block based storage” such as EBS. This means you can store large data sets as CSV files on Amazon S3 at a fraction of the price it would cost to store the data using EBS or in a relational database. You are then charged for each query (currently $5 per 5TB scanned). Clever use of compression and partitioning can reduce the amount of data scanned, meaning queries will be cheaper. AWS Athena is described as serverless which means the end user doesn’t need to manage or administer any servers, this is all done by AWS.
Save more using compression, partitioning and columnar data formats
If you notice from the previous paragraph that the query cost is $5 per 5TB scanned so the pricing is quite straightforward. Athena uses per megabyte charging, with a 10MB minimum. You can save by compressing, partitioning and/or converting data to a columnar format. The less data that needs to be scanned, the cheaper the query.
- Compression
- As Athena natively reads compressed files, the same query that works against a CSV file will also work against data compressed into one of the following formats:
- Snappy (.snappy)
- Zlib (.bz2)
- LZO
- GZIP (.gz)
- As less data is scanned, the overall cost is lower
- As Athena natively reads compressed files, the same query that works against a CSV file will also work against data compressed into one of the following formats:
- Partitioning
- Tables can be partitioned on any key. e.g. OrderDate
- If the query can use the key, there is no need to scan all the other partitions, only the relevant partition needs to be scanned.
- Compression and partitioning can be used together to further reduce the amount of scanned data.
- Converting to columnar
- Columnar formats such as ORC and Parquet are supported
- Converting may add complexity to your workload
- However it will save money on querying due to the columnar format, data scanned is reduced and speed is improved
- Here’s a tutorial, it will require an intermediate knowledge of EMR
Use Cases
- Apache Web Logs
- AWS CloudWatch logs
- System error logs
- Huge, infrequently accessed data sets which were extracted to a flat file format in S3
- Ad hoc querying of CSV files
Why is AWS Athena Awesome?
- There is no infrastructure to configure
- You only pay for what you scan
- If you compress, partition and convert your data into columnar formats, you can save up to 90%
- ANSI SQL Language is easy to learn or adapt from a dialect such as T-SQL
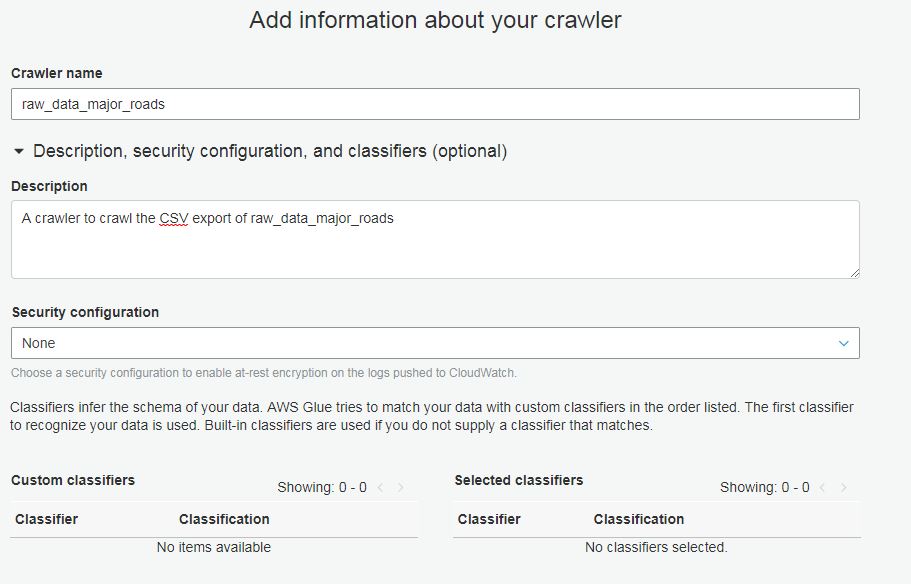
- Athena integrates with Glue to automate your ETL