The Glasgow Super Meetup was a joint event between Glasgow Azure User Group, Glasgow SQL User Group and Scottish PowerShell & DevOps User Group. I did an AWS Athena Presentation to the group.
Speaking about AWS Athena at the Glasgow Super Meetup might seem like an odd choice since most attendees will use Azure heavily or be more interested in SQL Server, however I was pleasantly surprised by the interest that people took in the subject matter. It was only a lightning talk so there wasn’t time to answer questions however I was asked a number of questions during the break by attendees.
I showed how tables can be archived out of the database and into S3, at a fraction of the price yet the data can still be queried if needed using Athena. I stressed that Athena isn’t intended as a replacement for an RDBMS and as such, queries will be slower than SQL Server however it is much cheaper to store large amounts of data in flat files in object storage (such as S3), rather than expensive block storage which is used with databases. So if the use case fits, such as infrequently accessed archive data, then it is something to consider. I’ve uploaded my slides and also linked to a recording of the event. If you want to try the code, you’ll find it below.
Demo
Description
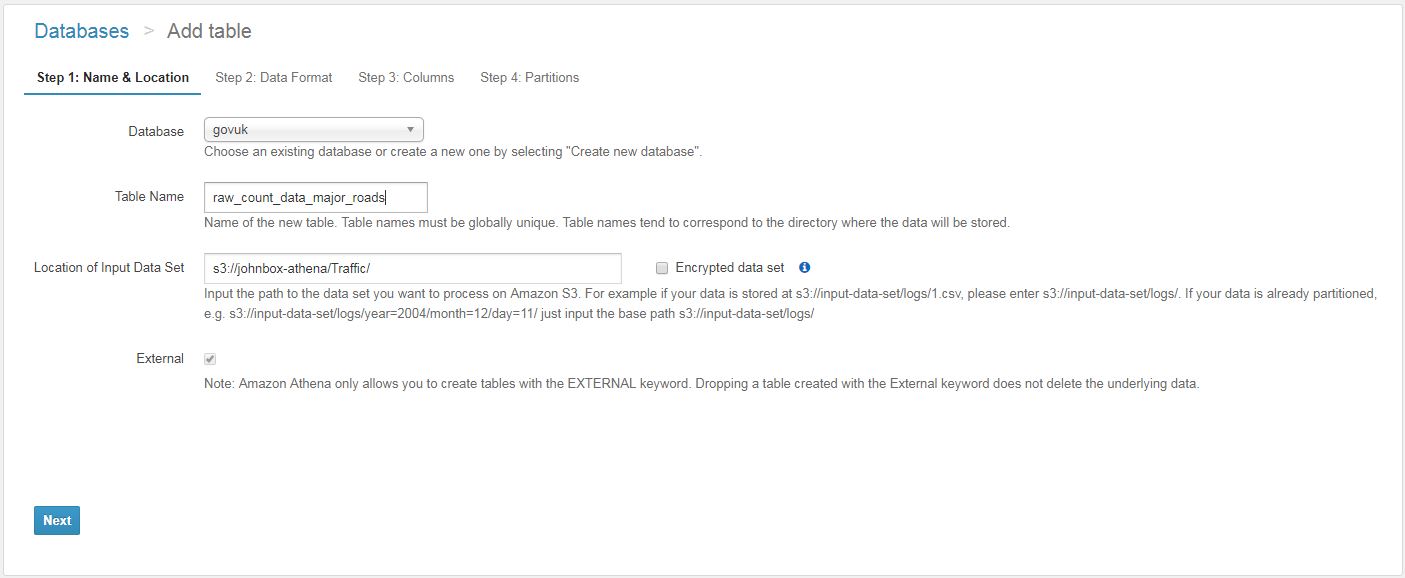
As a proof of concept, I want to export the data from the Sales.SalesOrderHeader table in Adventureworks2012 to flat files using BCP. The data would be partitioned into unique days using the OrderDate column. This data is then exported to the local file system and then uploaded to Amazon S3. The next steps include creating a table in Athena, querying it to review the data and validating the correct data has been uploaded.
Code
- Run select query with dynamic sql to generate PowerShell and BCP command. (Run query then select/copy full column and paste into PowerShell)
SELECT DISTINCT
OrderDate,
'New-Item -ItemType directory -Path C:\Users\jmccorma\Documents\SQL_to_S3_Demo\Output_Files\year='+CONVERT(varchar(4), OrderDate, 102)+'\month='+CONVERT(varchar(2), OrderDate, 101)+'\day='+CONVERT(varchar(2), OrderDate, 103)+' -ErrorAction SilentlyContinue' as PoSH_command,
'bcp "SELECT SalesOrderID, RevisionNumber, OrderDate, DueDate, ShipDate, Status, OnlineOrderFlag, SalesOrderNumber, PurchaseOrderNumber, AccountNumber, CustomerID, SalesPersonID, TerritoryID, BillToAddressID, ShipToAddressID, ShipMethodID, CreditCardID, CreditCardApprovalCode, CurrencyRateID, SubTotal, TaxAmt, Freight, TotalDue, Comment, rowguid, ModifiedDate FROM [AdventureWorks2012].[Sales].[SalesOrderHeader] WHERE OrderDate = '''+convert(varchar, OrderDate, 23)+'''"
queryout "c:\users\jmccorma\Documents\SQL_to_S3_Demo\Output_Files\year='+CONVERT(varchar(4), OrderDate, 102)+'\month='+CONVERT(varchar(2), OrderDate, 101)+'\day='+CONVERT(varchar(2), OrderDate, 103)+'\SalesOrderHeader.tsv" -c -t\t -r\n -T -S localhost\SQLEXPRESS' as bcp_command
FROM [AdventureWorks2012].[Sales].[SalesOrderHeader]
- Highlight column PoSH_command, copy and then paste into Powershell window
- Highlight column bcp_command, copy and then paste into Powershell or command window
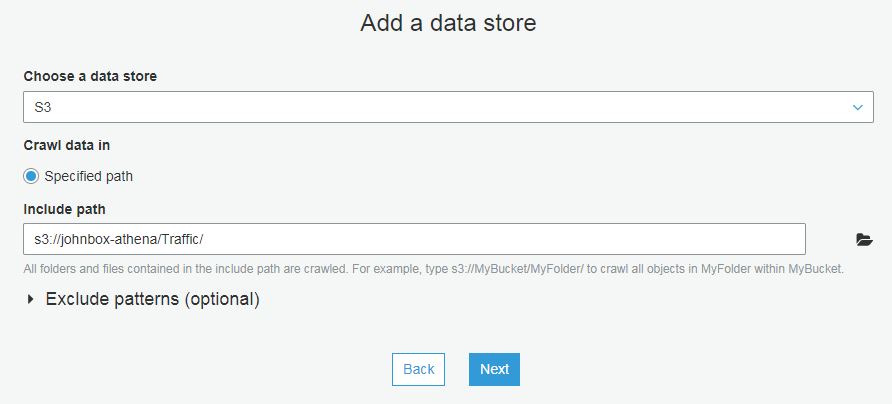
- Upload from local file system to AWS S3. You must have an S3 bucket created for this and you must have configured an IAM user in AWS to do this programatically. You can upload manually using the AWS console if you prefer.
aws s3 sync C:\SQL_to_S3_Demo\Output_Files s3://athena-demo-usergroup/Change to your local file location and your s3 bucket
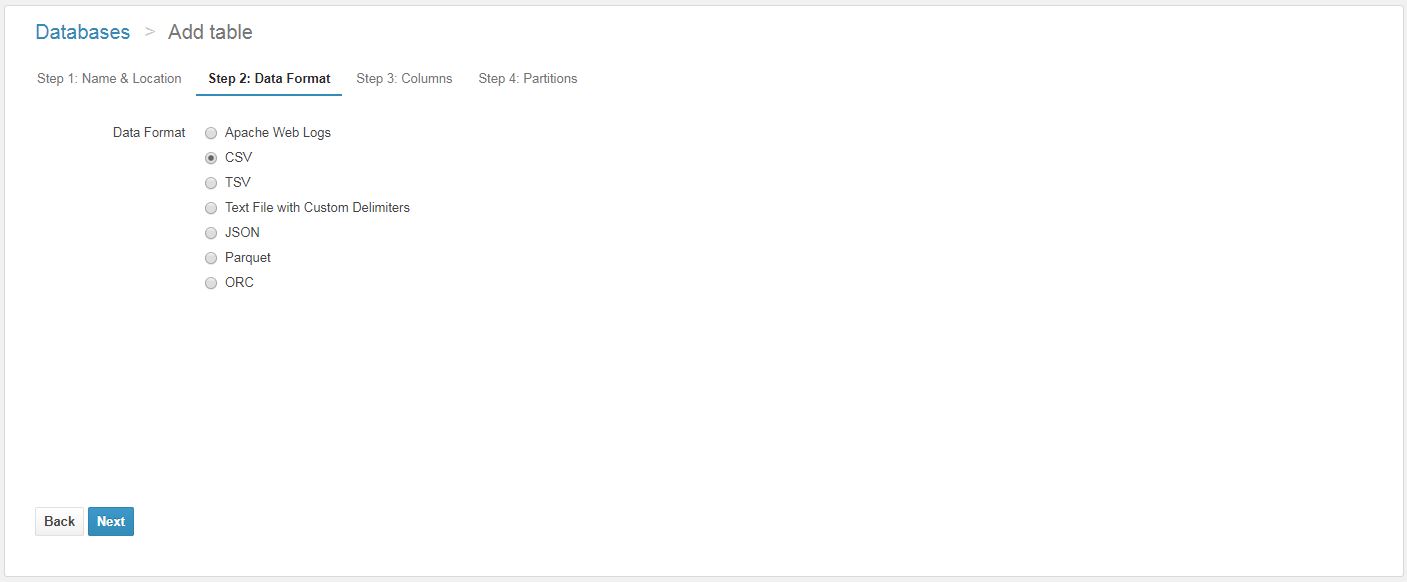
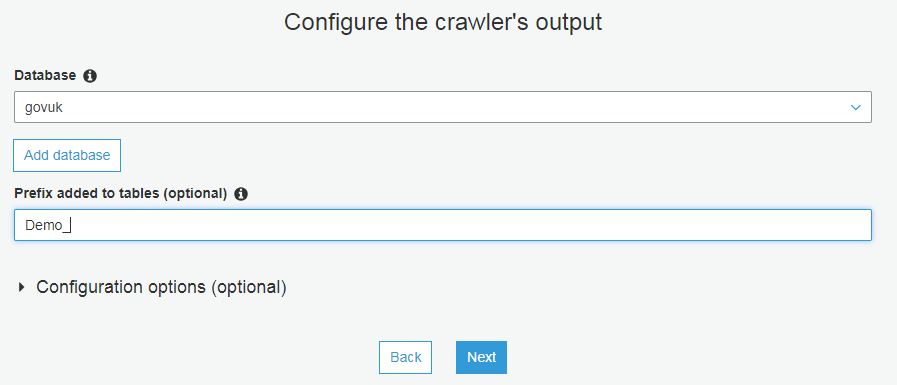
- Create database and table in Athena (copy code into AWS console) and load partitions
CREATE DATABASE adventureworks2012;-- Athena table created by John McCormack for Glasgow User Group
CREATE EXTERNAL TABLE `SalesOrderHeader`(
`SalesOrderID` INT,
`RevisionNumber` TINYINT,
`OrderDate` TIMESTAMP,
`DueDate` TIMESTAMP,
`ShipDate` TIMESTAMP,
`Status` TINYINT,
`OnlineOrderFlag` BOOLEAN,
`SalesOrderNumber` STRING,
`PurchaseOrderNumber` STRING,
`AccountNumber` STRING,
`CustomerID` INT,
`SalesPersonID` INT,
`TerritoryID` INT,
`BillToAddressID` INT,
`ShipToAddressID` INT,
`ShipMethodID` INT,
`CreditCardID` INT,
`CreditCardApprovalCode` STRING,
`CurrencyRateID` INT,
`SubTotal` DECIMAL(12,4),
`TaxAmt` DECIMAL(12,4),
`Freight` DECIMAL(12,4),
`TotalDue` DECIMAL(12,4),
`Comment` STRING,
`rowguid` STRING,
`ModifiedDate` TIMESTAMP
)
PARTITIONED BY (
`year` string,
`month` string,
`day` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION
's3://athena-demo-usergroup/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='0')
MSCK REPAIR TABLE salesorderheader;
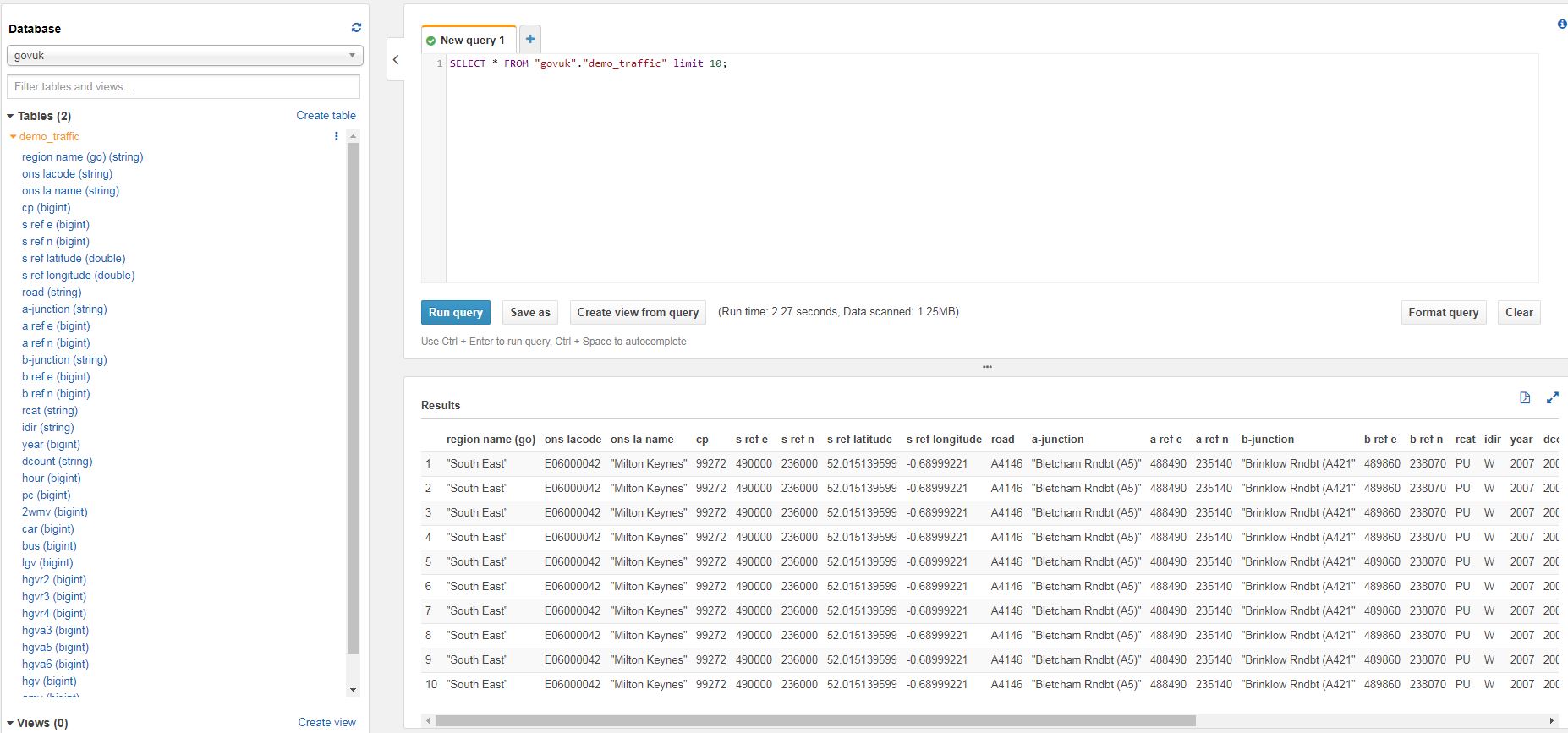
- Run these queries in SSMS and Athena to review the data is the same
- This performs a row count and checks the sum of one particular column(territoryid). This is fairly rudimentary check and not guaranteed to be unique but it is a simple way of having a degree of confidence in the exported data.
-- Validate Athena data is correct
-- Athena
SELECT COUNT(*) as row_count,SUM(territoryid) as column_sum FROM "adventureworks2012"."salesorderheader"
WHERE year='2014'
AND month = '01'
AND day = '23';-- SQL Server
SELECT COUNT(*) as row_count,SUM(territoryid) as column_sum FROM adventureworks2012.sales.salesorderheader
WHERE OrderDate = '2014-01-23 00:00:00.000'
- Now it is uploaded, you can query any way you like in Athena. It is worth noting that partitioning improves the performance of the query and makes the query cheaper because it scans less data. If partitioning data, you should use the partition key in your query otherwise it will scan all of data. Note the difference between the 2 queries below.
-- Not using partition (12 seconds - scanned 7.53MB)
SELECT * FROM "adventureworks2012"."salesorderheader"
WHERE OrderDate = CAST('2014-01-23 00:00:00.000' as TIMESTAMP);-- Using Partition (1.8 seconds - scanned 15.55KB - 1/6 of the duration and 1/495 of cost)
SELECT * FROM "adventureworks2012"."salesorderheader"
WHERE year='2014'
AND month = '01'
AND day = '23';
Further resources:


 This post specifically discusses how to write your EC2 SQL Server Backups to Amazon S3. It should not be confused with running SQL Server on RDS which is Amazon’s managed database service. To back up to S3, you will need to have an AWS account and a bucket in S3 that you want to write to. You’ll also need a way of authenticating into S3 such as an
This post specifically discusses how to write your EC2 SQL Server Backups to Amazon S3. It should not be confused with running SQL Server on RDS which is Amazon’s managed database service. To back up to S3, you will need to have an AWS account and a bucket in S3 that you want to write to. You’ll also need a way of authenticating into S3 such as an