 I left what I considered to be a great permanent job to become a DBA contractor in Glasgow. It was one where I could pick some of my own projects, work with new and interesting technology and work in a team which collaborated well, liked each other and were good at sharing knowledge.
I left what I considered to be a great permanent job to become a DBA contractor in Glasgow. It was one where I could pick some of my own projects, work with new and interesting technology and work in a team which collaborated well, liked each other and were good at sharing knowledge.
My reasons for moving on were two-fold. First of all, I wanted some career progression and it unfortunately just wasn’t available in my permanent job. Secondly, I wanted to work more with SQL Server and Azure. My last job started out as a SQL DBA but as a lot of people in this line of work will know, the duties have evolved considerably over time. This is mostly due to large scale cloud adoption. In my case, my workplace started heavily using AWS along with other RDBMSs and data platforms. (RDS MySQL & Aurora, ElasticSearch, Elastic Map Reduce (EMR), Glue and Athena). This gives you a lot to learn. Don’t get me wrong, I threw myself into learning about cloud solutions and I loved working with AWS (hopefully I will again) but as time went on, I was worried I would start to lose some SQL Server knowledge.
So what has the first month been like?
I have been working exclusively on the Microsoft Data Platform. At my first client, I’ve worked with SQL Server on-premises, SQL Server running on Azure VMs, Azure SQL DB, Azure Analysis Services and Azure SQL Data Warehouse.
On-Premises
The on-prem SQL Servers are mostly for hosting the databases of legacy applications and 3rd party vendor products. Some of the versions are ‘rather old‘ although these instances actually give the business the fewest headaches. I’ve worked on decommissioning unused databases that were still online, server side traces and native backups.
Azure VMs running SQL Server (IaaS)
These host the databases that have the most active development work. I’ve looked at performance issues and SQL Server configurations to help improve performance. I’ve shared best practice with the team in terms of tempdb and helped to reduce the volume of unnecessary emails from servers. (You know the ones which someone set up years ago but never induce any action from the DBAs).
Azure Analysis Services (PaaS)
This was fun. I only did some basic configuration and permissions but as I’ve never used Analysis Services much over the years, it was cool to see what was involved.
Azure SQL Data Warehouse (Paas)
It was great to get my hands on tech like this. I spent time modernising their manual point and click refresh process with PowerShell. This was a bit of a learning curve but extremely rewarding. This process will make future refreshes much easier. (I’ll share the code once I’m confident it’s good, I’d still like a few more run-throughs before doing this). Next month, I’d like to try to implement a self service process for the developers that allows them to do their own refreshes, freeing up DBA time to work on more critical items.
Azure SQL DB (PaaS)
So far, I haven’t had to do too much with Azure SQL DB on this project. I’ve listed out the instances and instance types using PowerShell. My plan is to review if these are right sized or if efficiencies can be made and I’ll also make sure the alerting is set up correctly.
Plans for next month
I’d like to offer some in depth server health reviews and work with the developers to help them make their code run faster. There is a lot of blocking due to long running stored procedures and sub optimal code. Improving a few of the big hitters will make them much happier and will ease the strain on some of our servers – at least that’s the idea.

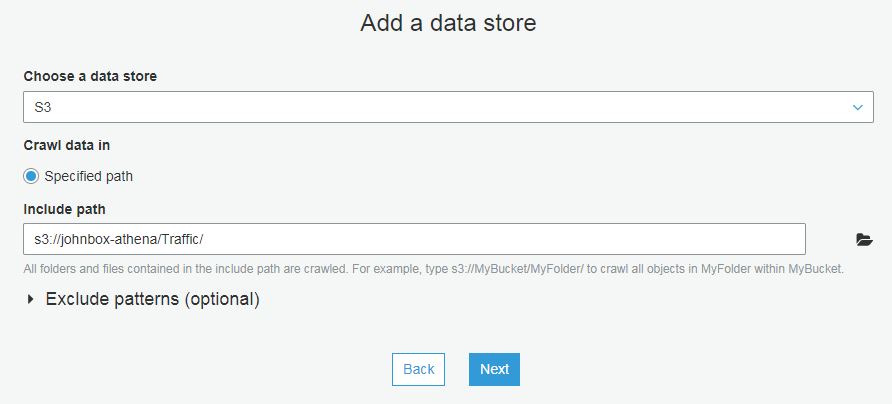

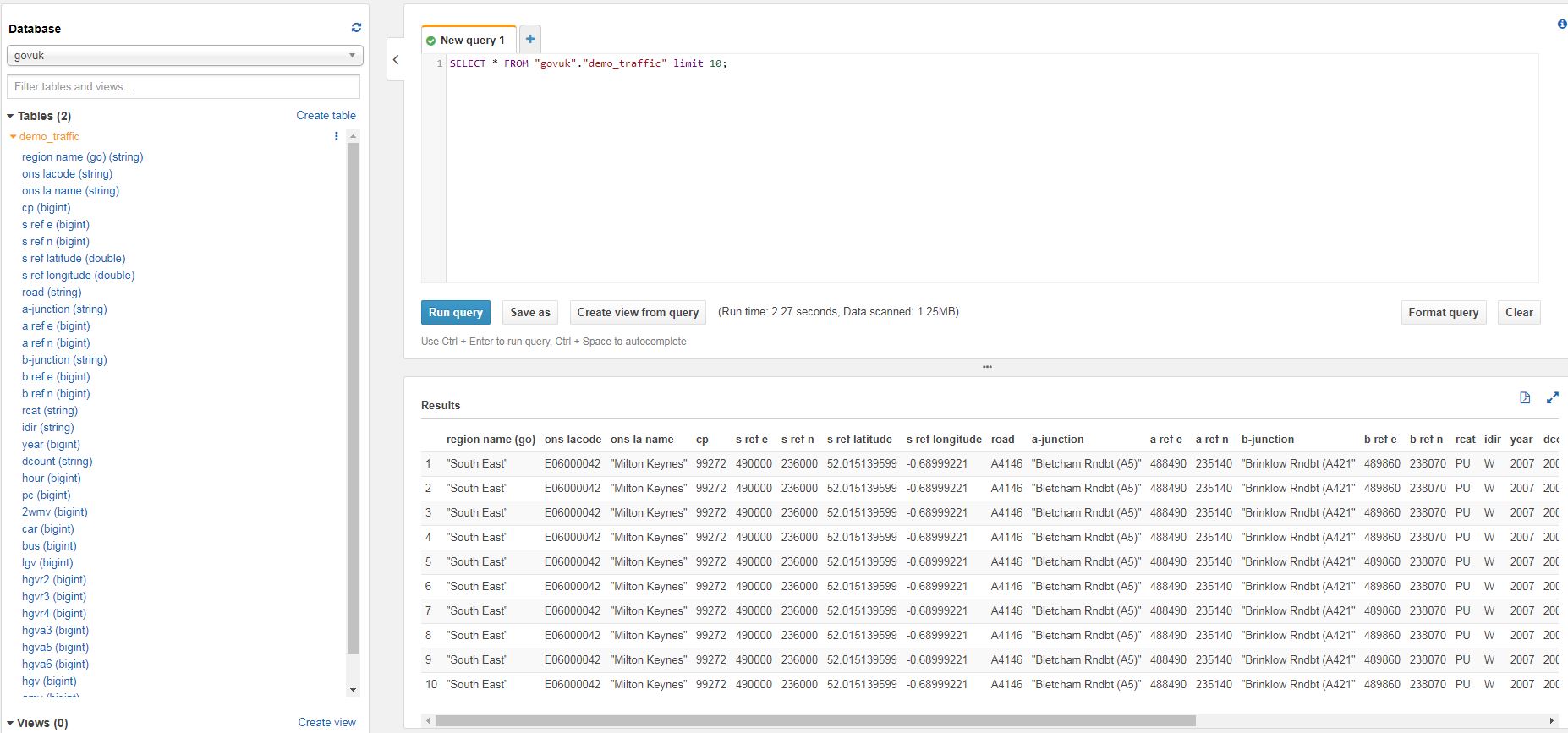
 This post about deleting data from a data warehouse is my first post in the
This post about deleting data from a data warehouse is my first post in the