How to create a table in AWS Athena
Before you learn how to create a table in AWS Athena, make sure you read this post first for more background info on AWS Athena.
Background
When you create a table in Athena, you are really creating a table schema. The underlying data which consists of S3 files does not change. You are simply telling Athena where the data is and how to interpret it. Therefore, tables are just a logical description of the data. Just like a traditional relational database, tables also belong to databases. Therefore, databases are also logical objects, which exist to group a collection of tables together. Databases and tables do not need to be created before the data is placed in to AWS S3. Similarly, if a table or database is dropped, the data will remain in S3.
All DDL statements in Athena use HiveQL DDL. Thankfully, you don’t need to be an expert in HiveQL DDL to create tables, you can learn as you go along. You can even use a wizard in the AWS console to create tables. You can script out the DDL from existing tables using the Athena console and this will give you guide for future tables.
The data used in the demo is a free download from data.gov.uk. They also have loads of data in various formats which you can use for testing.
About HiveQL DDL
Some syntax in HiveQL DDL is similar to ANSI SQL however there are are few key differences.
CREATE TABLEshould included the keyword EXTERNAL.CREATE EXTERNAL TABLEROW FORMAT SERDE– This describes which SerDe you should use. (More about that in the about SerDe section)SERDEPROPERTIES– e.g a set of rules which is applied to each row that is read, in order to split the file up into different columns. If you are not sure about this, read up more on SerDeLOCATION– the S3 bucket and folder where the data resides. No filename is required, just the location. e.g. s3://testathenabucket/traffi
About SerDe
SerDes are libraries which tell Hive how to interpret your data. SerDe is short for Serializer/Deserializer. There are a few to choose from that Athena supports and you cannot currently add you own.
- Apache Web Logs
- org.apache.hadoop.hive.serde2.RegexSerDe
- CSV
- org.apache.hadoop.hive.serde2.OpenCSVSerde
- TSV
- org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
- Custom Delimiters
- org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
- Parquet
- org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
- Orc
- org.apache.hadoop.hive.ql.io.orc.OrcSerde
- JSON
- org.apache.hive.hcatalog.data.JsonSerDe
- org.openx.data.jsonserde.JsonSerDe
Create a table in AWS Athena using Create Table wizard
You can use the create table wizard within the Athena console to create your tables. Just populate the options as you click through and point it at a location within S3. You must have access to the underlying data in S3 to be able to read from it. This method is slightly laborious as a result of all the screens and dropdowns, however it is reasonable enough when you only need to create a small number of tables.
Add Table
First of all, select from an existing database or create a new one. Give your table a name and point to the S3 location.
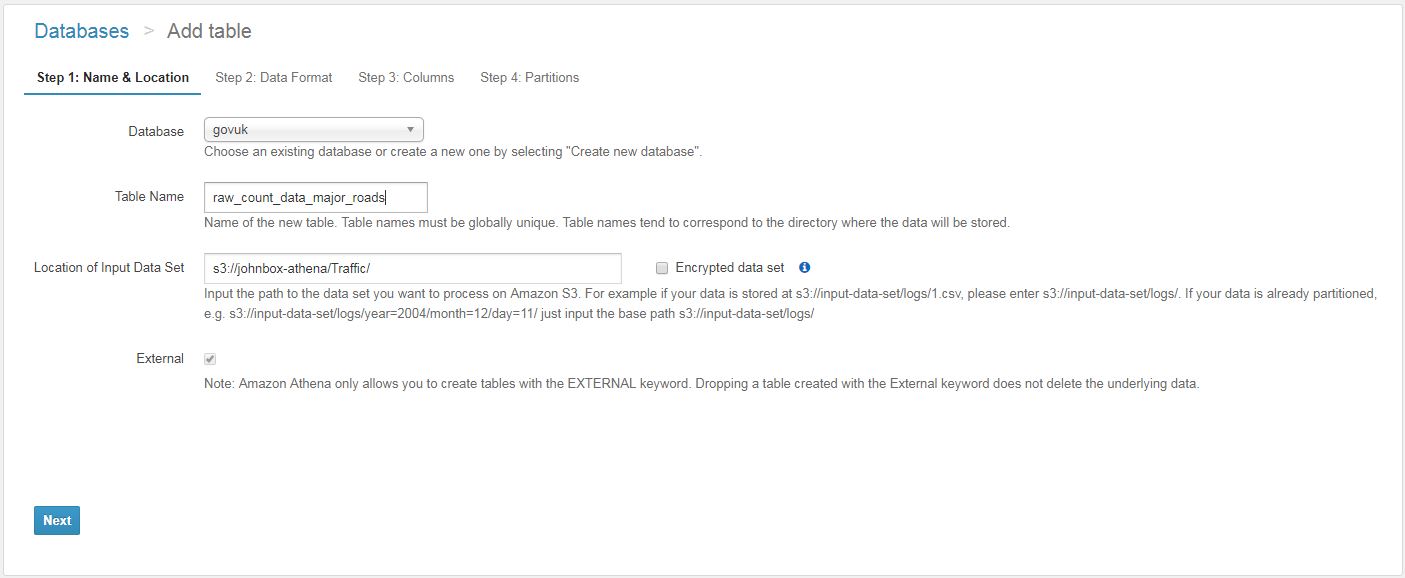
Data format
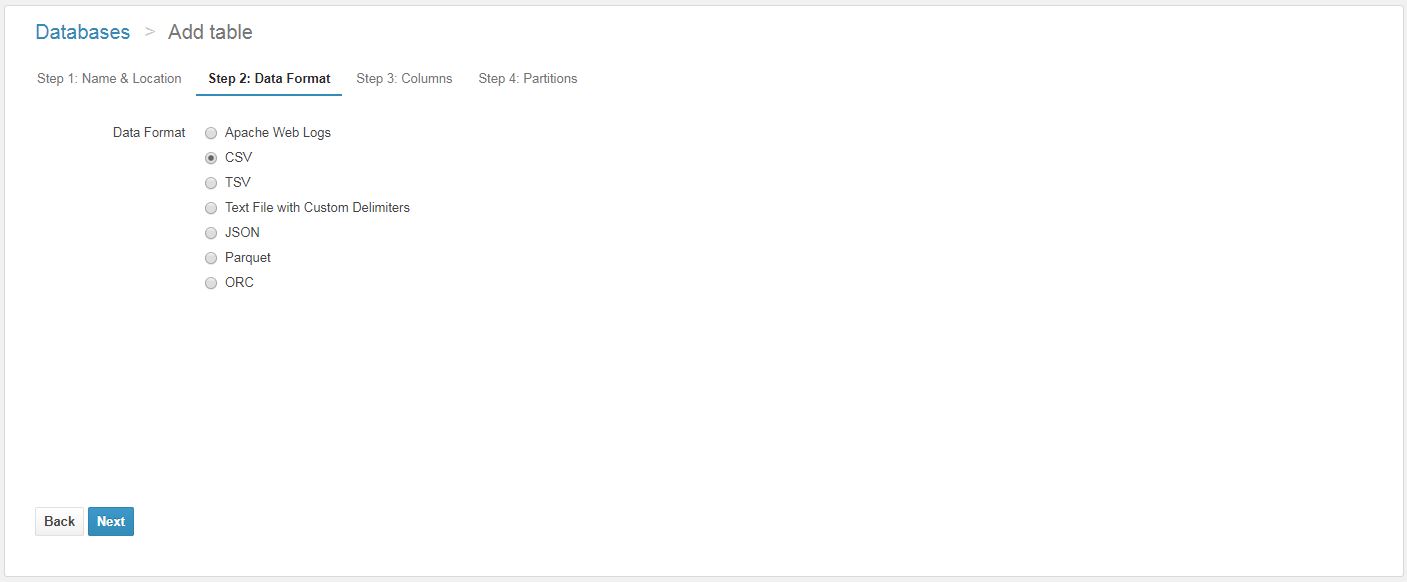
Various data formats are acceptable. Parquet and ORC are compressed columnar formats which certainly makes for cheaper storage and query costs and quicker query results. Other formats such as JSON and CSV can also be used, these can be compressed to save on storage and query costs however you would still select the data format as the original data type. e.g. For .csv.gz – you would choose CSV.
Columns
Column names and data types are selected by you. As a result, you need to know the structure of your data for this (or open the file to check)

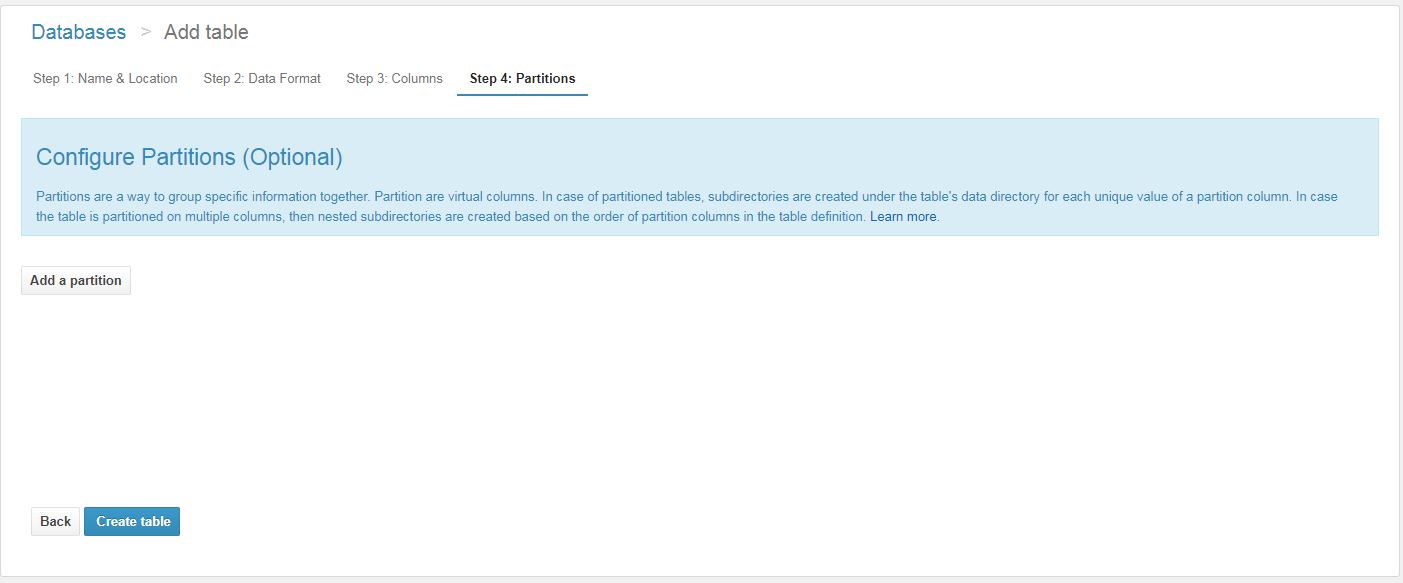
Partitions
Above all, data should be partitioned where appropriate, such as by day or by customer ID. Wherever it makes sense as this will reduce the amount of data scanned by Athena which reduces cost and improves query performance even more than compression alone.
Create a table in AWS Athena automatically (via a GLUE crawler)
An AWS Glue crawler will automatically scan your data and create the table based on its contents. Due to this, you just need to point the crawler at your data source. Once created, you can run the crawler on demand or you can schedule it. Hence, scheduling is highly effective for loading in new data and updating data where underlying files have changed.
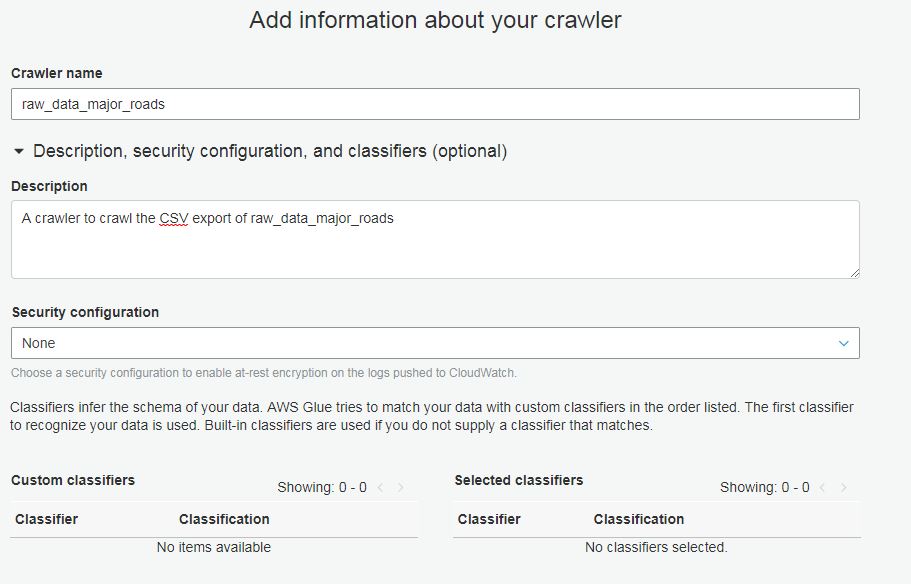
Give your crawler a name and description
Point the crawler to your data store.
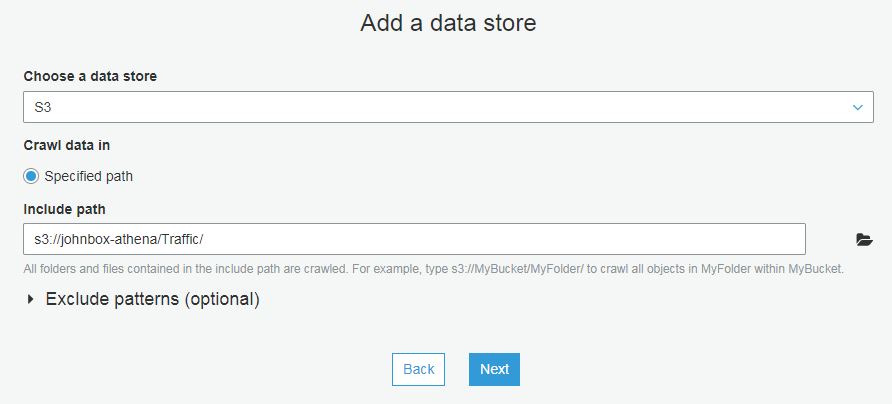
Select or create an IAM role. The crawler runs under an IAM role which must have the correct permission to create tables and read the data from S3.

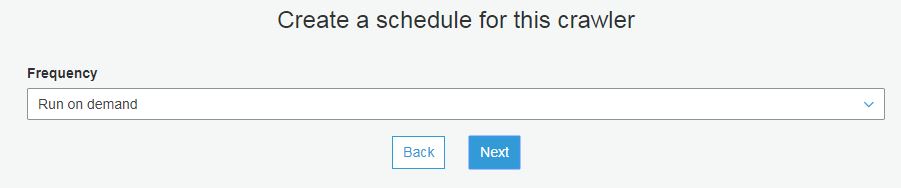
Choose a schedule for your Glue Crawler.
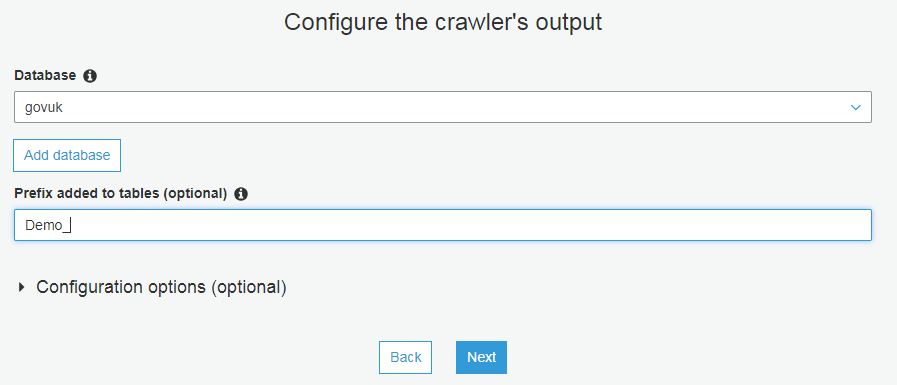
Declare the output location for your data.
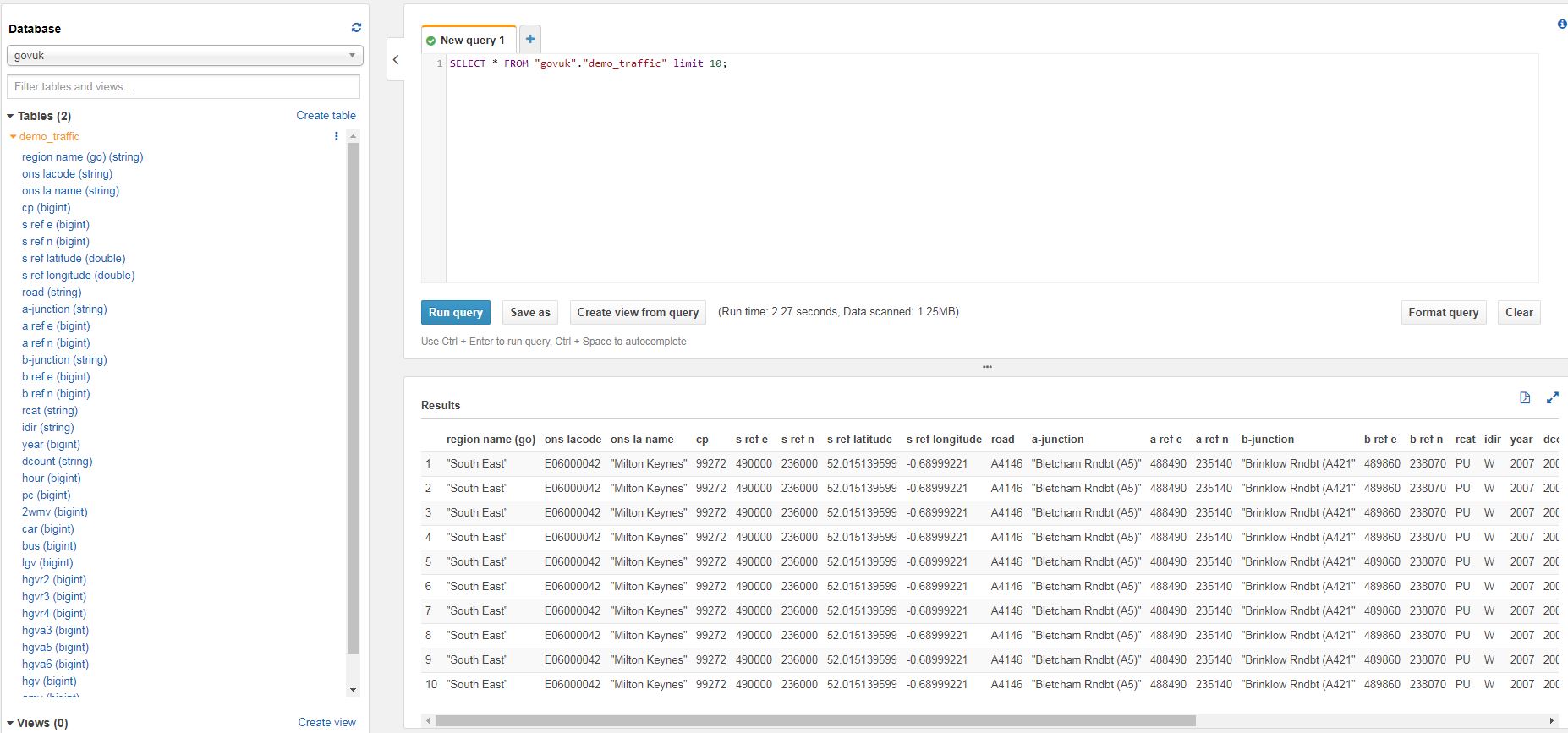
Finally, query your data in Athena. You can type SQL into the new query window, or if you just want a sample of data you can click the ellipses next to the table name and click on preview table.
Create a table in AWS Athena using HiveQL (Athena Console or JDBC connection)
This method is useful when you need to script out table creation. As well as the AWS Athena console, you can also use programs such SQL Workbench/J which rely on a JDBC connection.
CREATE EXTERNAL TABLE `demo_traffic`( `region name (go)` string, `ons lacode` string, `ons la name` string, `cp` bigint, `s ref e` bigint, `s ref n` bigint, `s ref latitude` double, `s ref longitude` double, `road` string, `a-junction` string, `a ref e` bigint, `a ref n` bigint, `b-junction` string, `b ref e` bigint, `b ref n` bigint, `rcat` string, `idir` string, `year` bigint, `dcount` string, `hour` bigint, `pc` bigint, `2wmv` bigint, `car` bigint, `bus` bigint, `lgv` bigint, `hgvr2` bigint, `hgvr3` bigint, `hgvr4` bigint, `hgva3` bigint, `hgva5` bigint, `hgva6` bigint, `hgv` bigint, `amv` bigint) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://johnbox-athena/Traffic/' TBLPROPERTIES ( 'compressionType'='none', 'delimiter'=',', 'objectCount'='1', 'skip.header.line.count'='1', 'typeOfData'='file')
Further resources
- https://johnmccormack.it/2018/03/introduction-to-aws-athena/
- https://docs.aws.amazon.com/athena/latest/ug/create-table.html
- https://data.gov.uk/search?filters%5Btopic%5D=Transport
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDLHiveQL DDL
 This post about deleting data from a data warehouse is my first post in the
This post about deleting data from a data warehouse is my first post in the  This post specifically discusses how to write your EC2 SQL Server Backups to Amazon S3. It should not be confused with running SQL Server on RDS which is Amazon’s managed database service. To back up to S3, you will need to have an AWS account and a bucket in S3 that you want to write to. You’ll also need a way of authenticating into S3 such as an
This post specifically discusses how to write your EC2 SQL Server Backups to Amazon S3. It should not be confused with running SQL Server on RDS which is Amazon’s managed database service. To back up to S3, you will need to have an AWS account and a bucket in S3 that you want to write to. You’ll also need a way of authenticating into S3 such as an  I had the pleasure of speaking at last night’s SQL Server Meetup in Glasgow. It was a fairly relaxed affair and I hope that the session was enjoyed by those who attended.
I had the pleasure of speaking at last night’s SQL Server Meetup in Glasgow. It was a fairly relaxed affair and I hope that the session was enjoyed by those who attended. As I troubleshoot performance problems with SQL Server, I often find that the configuration of the TempDB system database can be a cause, or a major contributor to poor performance. It is amongst the most prolific offenders and is an easy fix. In previous versions of SQL Server, TempDB was a bit of an afterthought when it came to installation however with SQL Server 2016, you can set it up the way you want from the outset, albeit with some minor restrictions.
As I troubleshoot performance problems with SQL Server, I often find that the configuration of the TempDB system database can be a cause, or a major contributor to poor performance. It is amongst the most prolific offenders and is an easy fix. In previous versions of SQL Server, TempDB was a bit of an afterthought when it came to installation however with SQL Server 2016, you can set it up the way you want from the outset, albeit with some minor restrictions.