SQL Server on Amazon RDS Course
I’ve put together a short video series on running SQL Server on Amazon RDS. It covers some basics and can be completed in around an hour, with several very short videos. It’s intended for SQL professionals who are just getting started with AWS, but might also be enjoyed by AWS users, looking to get started with a relational database management system.
It’s my first attempt at putting together a training plan. So any feedback will be gratefully received. Either in the blog comments or YouTube video comments.
Contents
1. Introduction to SQL Server on Amazon RDS (Scroll down)
2. Benefits and limitations of AWS RDS
3. Create your first RDS instance using the AWS console
4. Connecting to your AWS RDS instance
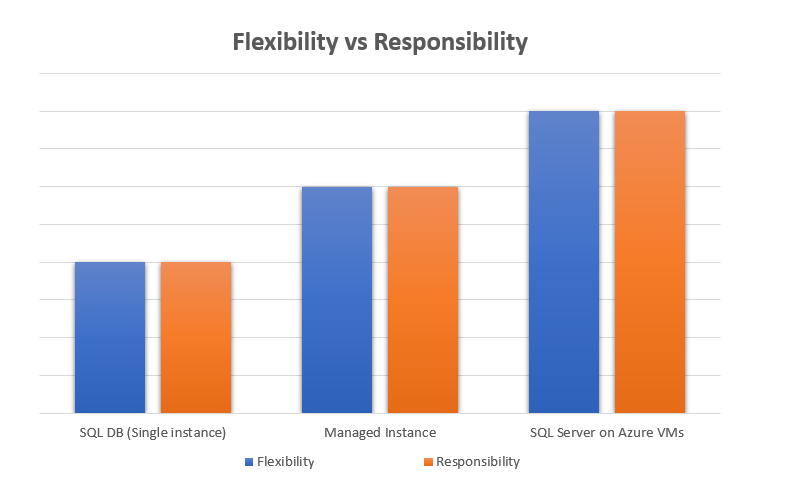
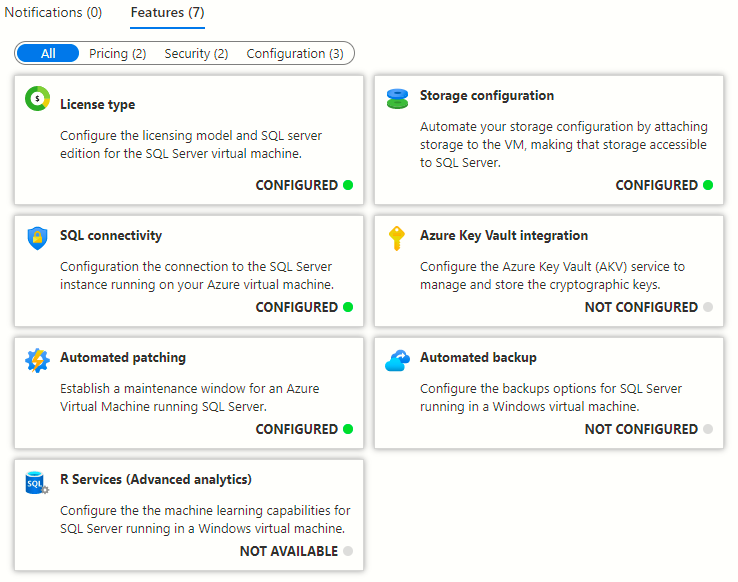
5. Advanced Configurations using Parameter Groups
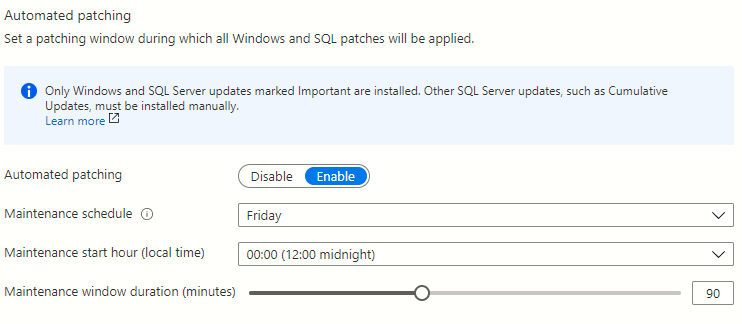
6. Securing your SQL Server AWS RDS Instance
7. Automating Deployments using PowerShell
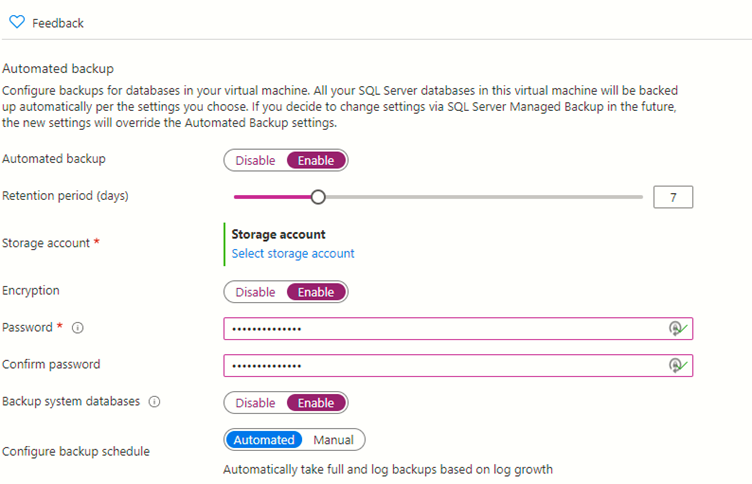
8. Backup and restore for AWS RDS
9. Providing High-Availability through Multiple Availability Zones
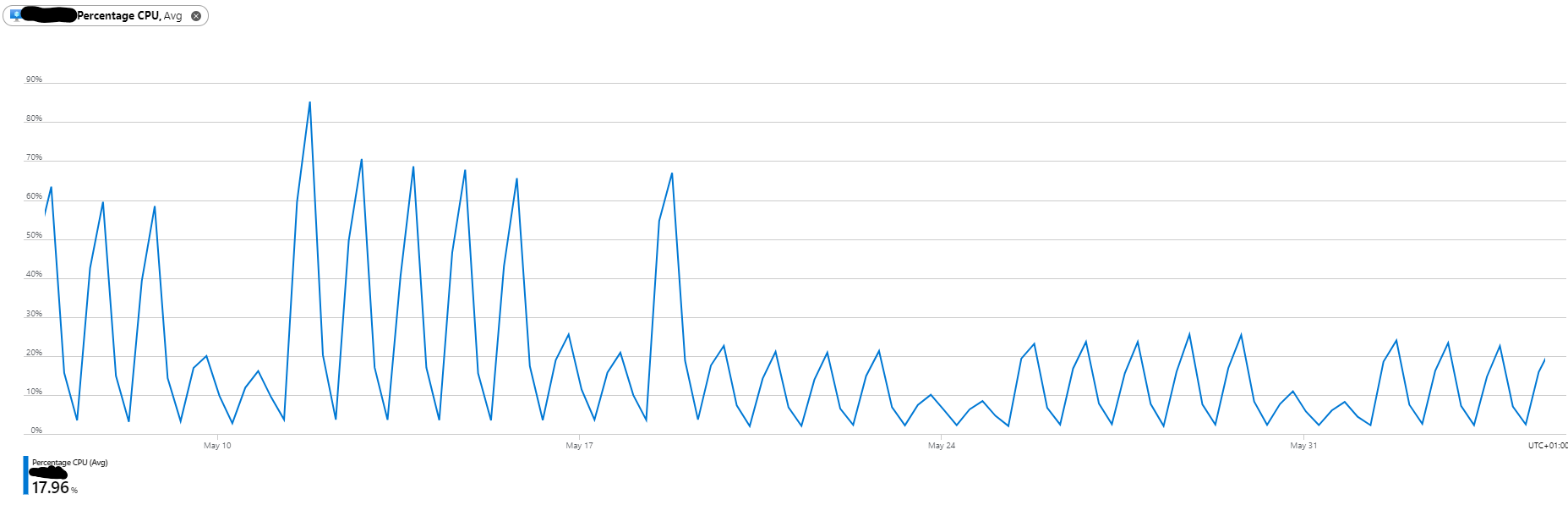
10. Monitoring Your Instances using CloudWatch
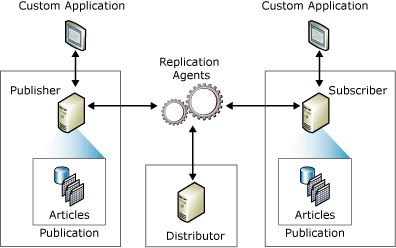 This might make me the odd one out but I actually really like replication. It took me a while to get comfortable with it but when I did and when I learned how to troubleshoot transactional replication confidently, I became a fan. Since I exclusively use transactional replication and not snapshot replication or merge replication, this post is only about transactional replication and in particular, how to troubleshoot transactional replication errors.
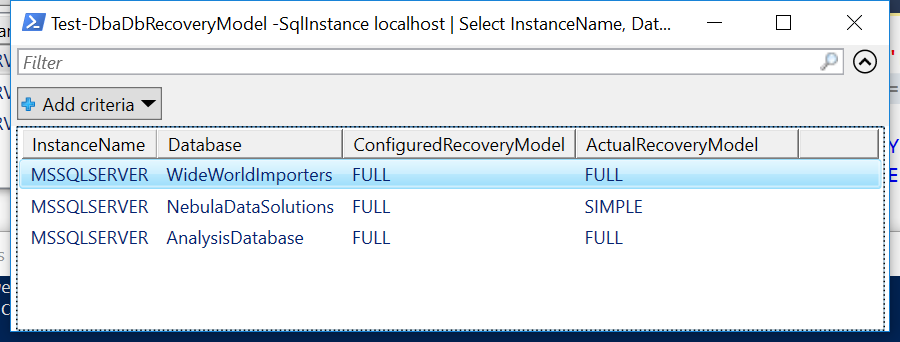
This might make me the odd one out but I actually really like replication. It took me a while to get comfortable with it but when I did and when I learned how to troubleshoot transactional replication confidently, I became a fan. Since I exclusively use transactional replication and not snapshot replication or merge replication, this post is only about transactional replication and in particular, how to troubleshoot transactional replication errors. This post is about database recovery models for SQL Server databases. Having the correct recovery model for a database is crucial in terms of your backup and restore strategy for the database. It also defines if you need to do maintenance of the transaction log or if you can leave this task to SQL Server. Let’s look at the various recovery models and how they work.
This post is about database recovery models for SQL Server databases. Having the correct recovery model for a database is crucial in terms of your backup and restore strategy for the database. It also defines if you need to do maintenance of the transaction log or if you can leave this task to SQL Server. Let’s look at the various recovery models and how they work.