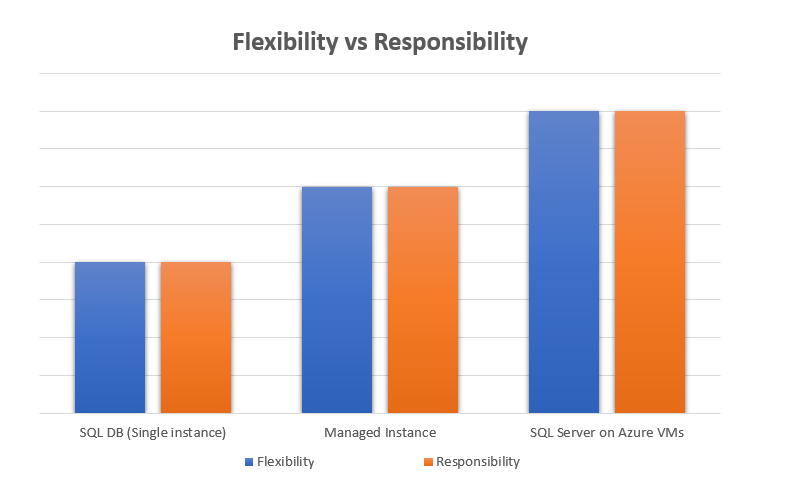
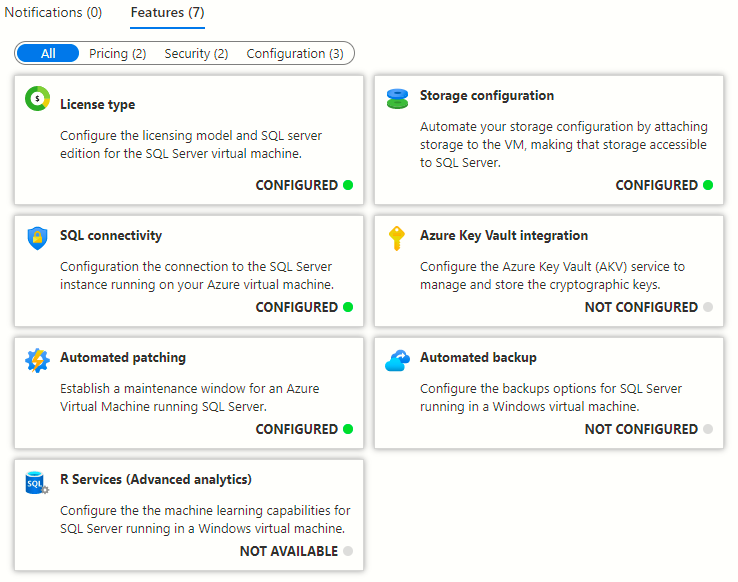
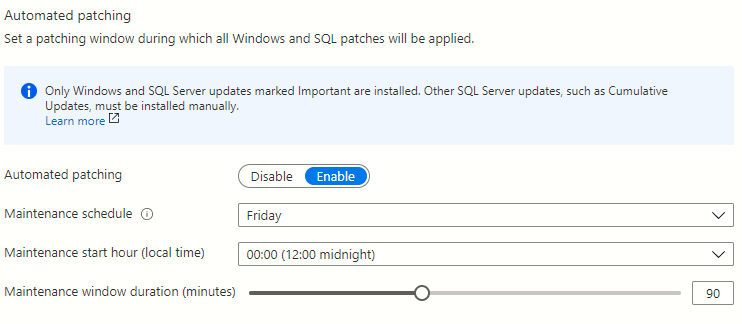
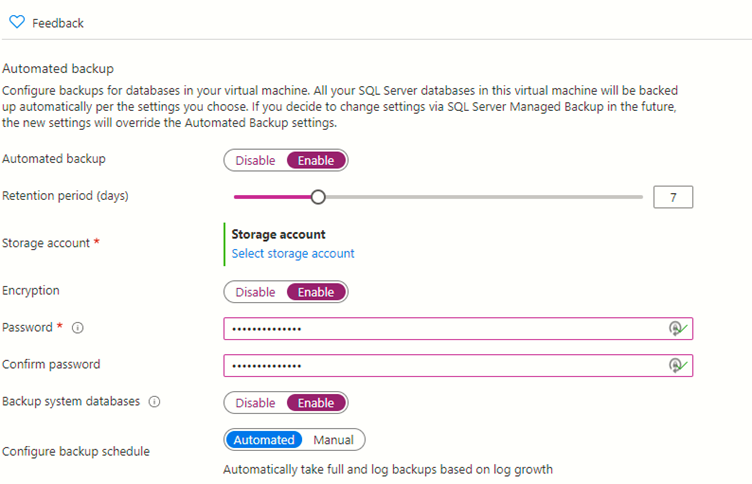
I just realised that in all my scripts that I use on a regular basis, I didn’t have one for working out free space in SQL Server filegroups. It’s not something that comes up too often but it’s handy to know. For methods of working out space in individual files, you could refer to this post on mssqltips.
-- Free space by filegroup SELECT FILEGROUP_NAME(data_space_id) as FilegroupName, SUM(size/128.0) AS CurrentSizeMB, SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS FreeSpaceMB, ( SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) / -- FreeSpaceMB (SUM(size/128.0)) -- CurrentSizeMB * 100 -- Convert to percentage ) AS FilegroupPercentFree, COUNT(*) as NumberOfFilesInFilegroup FROM sys.database_files WHERE data_space_id <> 0 GROUP BY FILEGROUP_NAME(data_space_id);

POST #100
I just realised as well that this is post #100 on my blog. I started it just to save some of my queries and ideas. Post #1 was a really simple query but it got me going.
 This post is part of the October 2020 edition of
This post is part of the October 2020 edition of